Spam Filter- Machine Learning
A spam filter is software that is designed to detect and classify unwanted emails, also known as spam, from legitimate messages. One of the most effective ways to achieve this is through the use of machine learning.

Machine learning is a method of teaching computers to learn from data without being explicitly programmed. This allows for the creation of algorithms that can identify patterns and make predictions based on input data. In the case of spam filters, machine learning algorithms are trained on a dataset of both spam and legitimate emails, allowing them to learn the characteristics that distinguish the two types of messages.
There are a few different types of machine learning algorithms that are commonly used in spam filters.
- One popular method is the use of Bayesian filters, which use Bayes' theorem to calculate the probability that an email is spam based on the presence of certain words or phrases.
- Another method is the use of support vector machines (SVMs), which can effectively classify emails based on a set of features, such as the sender's email address or the presence of certain words in the subject line.
One of the key advantages of using machine learning for spam filtering is its ability to adapt to new types of spam. As spamming techniques evolve, traditional rule-based spam filters can quickly become outdated. Machine learning algorithms, on the other hand, are able to learn from new examples and adjust their classifications accordingly.
However, machine learning-based spam filters are not without their limitations. One major issue is the need for a large and diverse dataset of both spam and legitimate emails for training. Without enough data, the algorithm may not be able to accurately distinguish between the two types of messages. Additionally, machine learning models can make mistakes, which can result in false positives (legitimate emails being classified as spam) or false negatives (spam emails slipping through the filter).
Now, using naive Bayes and a tagged dataset of emails received from Kaggle, we will develop a basic spam filter as an example. The several preparation methods for text data will also be explained, feature extraction and a classification model will follow it.
Importing Libraries
import nltk
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time
import re
from wordcloud import WordCloud
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
%matplotlib inline
Exploratory Data Analysis
emails_files = pd.read_csv('emails.csv')
emails_files.head()
Output:

# Reading one email
emails_files._get_value(58,'text')
Output:

# Total Emails in the dataset
emails_files.shape
Output:

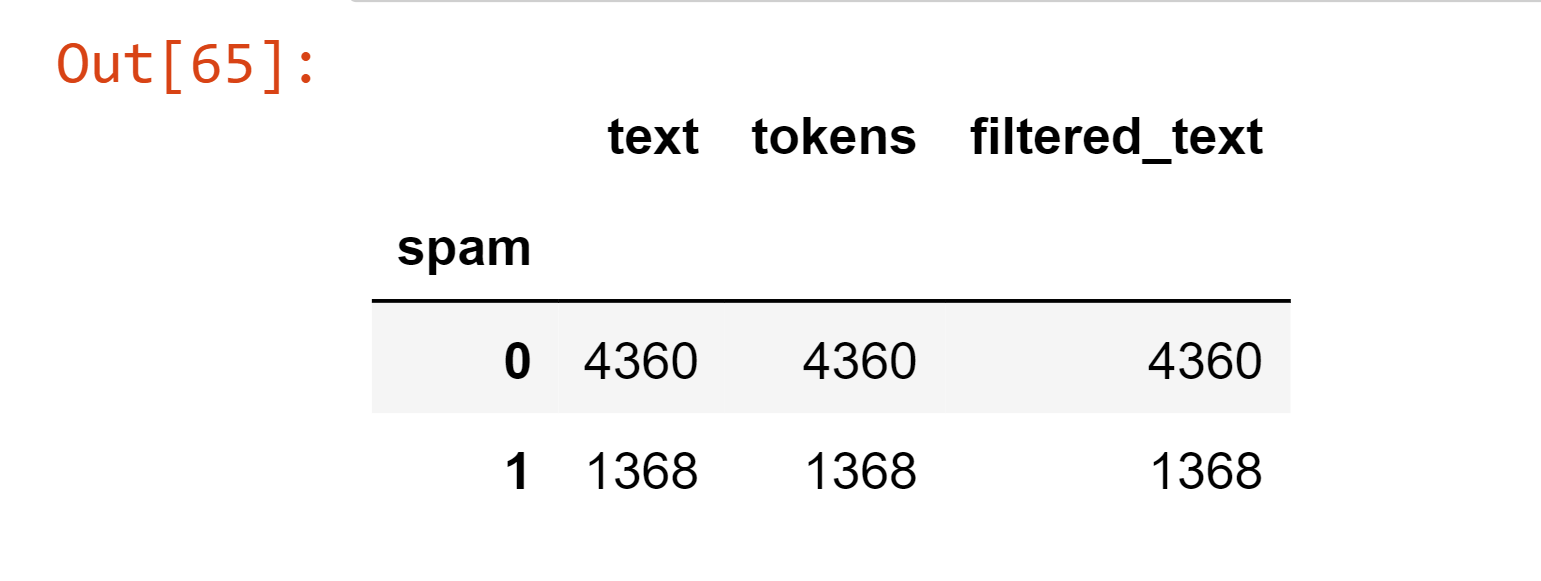
# Class Distribution
emails_files.groupby('spam').count()
# Spam makes up 23.88% of emails, which is plenty for our objective.
Output:
# Distribution of Spam using graphs
counts_labels = emails_files.spam.value_counts()
plt.figure(figsize = (12,6))
sns.barplot(counts_labels.index, counts_labels.values, alpha = 0.9)
plt.xticks(rotation = 'vertical')
plt.xlabel('Spam', fontsize =12)
plt.ylabel('Counts', fontsize = 12)
plt.show()
Output:
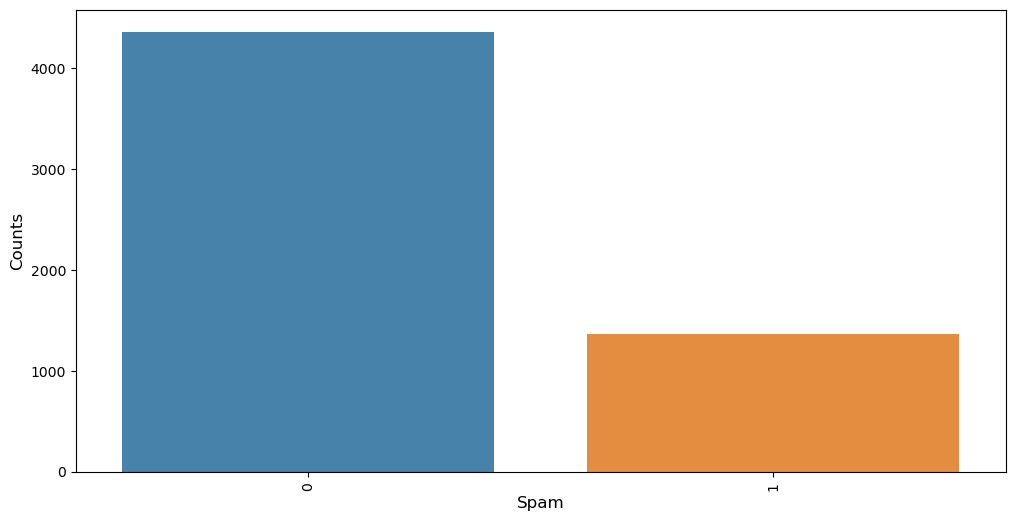
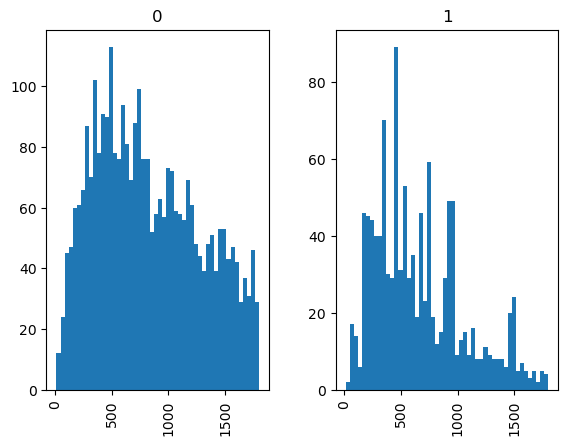
# Checking whether length of email is coorelated to spam
emails_files['length'] = emails_files['text'].map(lambda text: len(text))
emails_files.groupby('spam').length.describe()
Output:

# There are some severe outliers in emails' length; let's set length criteria and examine the distribution of length.
subset_of_emails = emails_files[emails_files.length < 1800]
subset_of_emails.hist(column='length', by='spam', bins=50)
# Nothing significant here; let's now process the mail's contents to develop a spam filter.
Output:
array([<AxesSubplot:title={'center':'0'}>,
<AxesSubplot:title={'center':'1'}>], dtype=object)
Data Preprocessing
Since the emails presented in the data are a disorganized mess, it's crucial to preprocess them before feature extraction and modeling. With just a few lines of Python code, this preprocessing is now quite simple, thanks to the nltk package.
Tokenization
Continuous word streams are tokenized, creating a unique token for each word.
import nltk
nltk.download('punkt')
emails_files['tokens'] = emails_files['text'].map(lambda text: nltk.tokenize.word_tokenize(text
Output:

# tokenized text from the 1st email
print(emails_files['tokens'][1])
Output:

Removal of Stop Words
Stop words often refer to the most prevalent terms in a language, such as "the," "a," and "as." Let's get rid of these terms because they often don't transmit any information that spam filters might find beneficial.
# Removing
import nltk
nltk.download('stopwords')
words_stops = set(nltk.corpus.stopwords.words('english'))
emails_files['filtered_text'] = emails_files['tokens'].map(lambda tokens: [w for w in tokens if not w in words_stops])
Output:

emails_files['filtered_text'] = emails_files['filtered_text'].map(lambda text: text[2:])
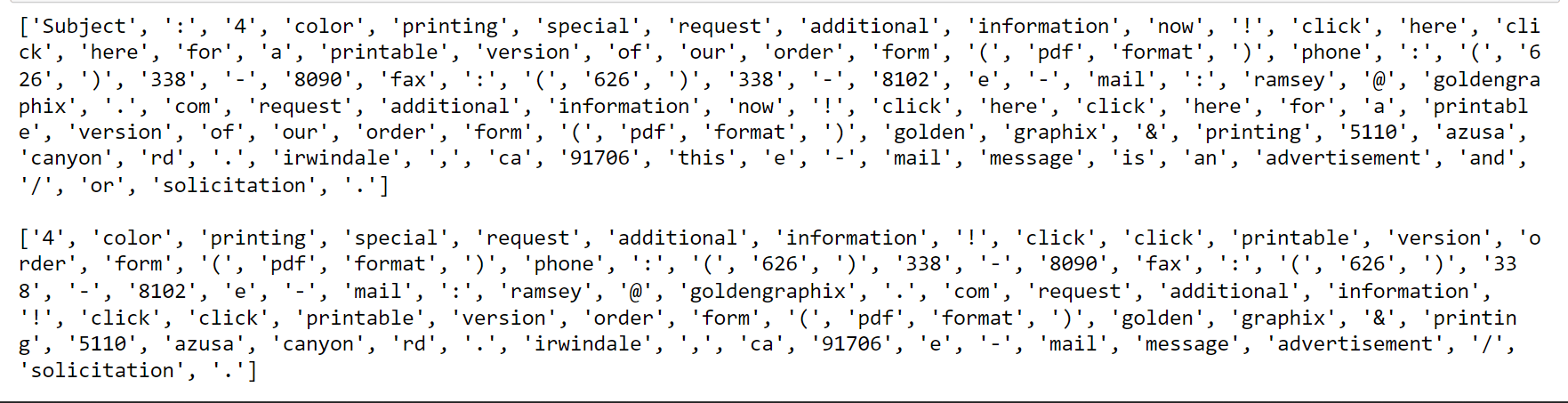
# Comparing email with the removed(words_stops) email.
print(emails_files['tokens'][3],end='\n\n')
print(emails_files['filtered_text'][3])
# several stop words like 'the', 'of' etc., were eliminated
Output:
# There are still a lot of special character tokens in emails that might not be useful for spam filters; let's get rid of them.
# forming a string by joining all tokens together
emails_files['filtered_text'] = emails_files['filtered_text'].map(lambda text: ' '.join(text))
# Taking special characters out of every email
emails_files['filtered_text'] = emails_files['filtered_text'].map(lambda text: re.sub('[^A-Za-z0-9]+', ' ', text))
Lemmatization
It's the procedure of combining a word's inflected forms so they may be examined as a single entity, distinguished by the word's lemma or dictionary form. The term "move" will be substituted for words like "moved" and "moving."
import nltk
nltk.download('wordnet')
wnl = nltk.WordNetLemmatizer()
emails_files['filtered_text'] = emails_files['filtered_text'].map(lambda text: wnl.lemmatize(text))
Output:

# Checking email after preprocessing
emails_files['filtered_text'][4]
Output:

# Wordcloud
words_spam = ''.join(list(emails_files[emails_files['spam']==1]['filtered_text']))
wordclod_spam = WordCloud(width = 512,height = 512).generate(words_spam)
plt.figure(figsize = (10, 8), facecolor = 'k')
plt.imshow(wordclod_spam)
plt.axis('off')
plt.tight_layout(pad = 0)
plt.show()
Output:

#Wordcloud of non-spam mail
spam_words = ''.join(list(emails_files[emails_files['spam']==0]['filtered_text']))
spam_wordclod = WordCloud(width = 512,height = 512).generate(spam_words)
plt.figure(figsize = (10, 8), facecolor = 'k')
plt.imshow(spam_wordclod)
plt.axis('off')
plt.tight_layout(pad = 0)
plt.show()
Output:

Models for Spam Filtering
After the text has been cleaned up enough through preprocessing, let's turn these emails into vectors of numbers using two well-liked techniques: TF-IDF and a Bag of Words. We will use Naive Bayes to create our classifier after obtaining vectors for each mail.
1. Bag of Words
In essence, it builds a vector containing the frequency of each word in a given mail's lexicon. As the name implies, a bag of words treats text as a collection of unconnected bags of words rather than a sequence. These vectors are simple to make using Scikit-CountVectorizer().
count_vect = CountVectorizer()
counts = count_vect.fit_transform(emails_files['filtered_text'].values)
print(counts.shape)
Output:

Naive Bayes Classifier
classifier_mnb = MultinomialNB()
targets = emails_files['spam'].values
classifier_mnb.fit(counts, targets)
Output:

# Prediciton
examples_to_predict = ['cheap Viagra', "Forwarding you minutes of meeting"]
example_counts = count_vect.transform(examples_to_predict)
predictions = classifier_mnb.predict(example_counts)
print(predictions)
Output:

2. TF-IDF
A word's importance to a collection of all mail or corpus is meant to be reflected by the tf-idf statistic, which is a numerical measure. The tf-idf values for each word in each message are likewise contained in this vector. To create this vector, in this case, we'll utilize the TfidfTransformer() function from Scikit Learn.
tfidf_vect = TfidfTransformer().fit(counts)
tfidf = tfidf_vect.transform(counts)
print(tfidf.shape)
Output:

classifier_mnb = MultinomialNB()
targets_ = emails_files['spam'].values
classifier_mnb.fit(counts, targets_)
Output:

#Predictions
examples_to_predict = ['Free Offer Buy now',"Lottery from Nigeria","Please send the files"]
example_counts = count_vect.transform(examples)
example_tfidf = tfidf_vect.transform(example_counts)
predictions_tfidf = classifier_mnb.predict(example_tfidf)
print(predictions_tfidf)
Output:
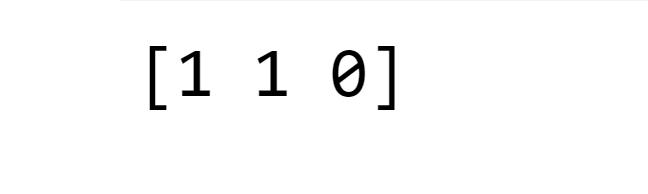
In conclusion, machine learning is a powerful tool for creating effective spam filters. These algorithms can learn to identify patterns and characteristics that distinguish spam from legitimate emails, which allows them to adapt to new types of spam. However, it's important to have a large, diverse dataset for training and understand that machine learning models can also make mistakes.