Natural Language Processing
Natural Language Processing in AI
Topics Covered in Language Module
- Natural Language Processing
- Syntax and Semantics
- Context-Free Grammar
- NLTK
- N-grams
- Tokenization
- Bag of Words
- Naïve Bayes
In language, we will cover how Artificial Intelligence is used to process human language and convert it into meaningful information that can be understood by the system and further convert the useful information into the form which can be understood by a human.
Natural Language Processing Algorithms
Natural Language Processing is the subfield of Artificial Intelligence, which deals with the interactions of human language and computers. It deals with the programs and techniques to analyze and process a large amount of human language data.
Examples of Natural Language Processing are:
- Automatic summarization- It is the system where the AI system takes input as text and returns the summary of the text as an output.
- Information extraction is an AI system where a large amount of unstructured or semi-structured machine-readable texts is given as an input, and the system returns the structured information as an output.
- Language identification- It is the system where any text is given as an input to an AI system, and it returns the language of the text as an output.
- Machine translation- It is the system where any text in its original language is given as an input, and the system converts the text into the target language and gives it as an output.
- Named entity recognition- It is the system when a text document is given as an input to the AI system, and the system extracts the names of the entities from the text document. For example, the names of companies.
- Speech recognition- It is the system where the AI system is given speech as an input, and it produces the text summary of the same words.
- Text classification- It is an AI where some text is given as an input where the AI is given text, and it needs to classify it as some text.
- Word sense disambiguation- In Word sense disambiguation AI system needs to choose the right meaning of the text, which is given to it as an input and which has multiple meanings. For example, a bank means both a financial institution and the ground on a river's sides.
Syntax and Semantics
Syntax: Syntax is the structure of the text. It is the arrangement of the words in a sentence in such a way that it makes sense. While speaking our native language, we don't pay attention to the grammatical mistakes in our sentences and yet understand the sentence's meaning.
For example, People usually make lots of mistakes while using "Your" and "You're," "Its" and "It's," Affect and Effect, etc.
In NLP, syntactic analysis is used to analyze the natural language. Different syntax techniques (Algorithms) are used to apply grammatical rules to the text document and extract meaning from them.
Semantics: Semantics is the meaning of words or sentences. Two completely different sentences can have the same meaning sometimes. For example, the sentence "Just before nine o'clock Sherlock Holmes stepped briskly into the room" is syntactically different from "Sherlock Holmes stepped briskly into the room just before nine o'clock," Bit meaning of both sentences is the same. Similarly, the other sentence, "A few minutes before nine, Sherlock Holmes walked quickly into the room," uses different words from the previous sentences, but it still contains the same meaning.
Also, a sentence can be perfectly grammatical and non-sensible at the same time. So, Semantics analysis is used to understand the content of the sentences. Different Algorithms and techniques are used to understand the meaning and structure of the sentences.
Context-Free Grammar
When certain rules are used for generating sentences in a language, then it's called Formal Grammar.
When the text is abstracted from the meaning of the sentence and represents the sentence structure using formal grammar.
For Example:
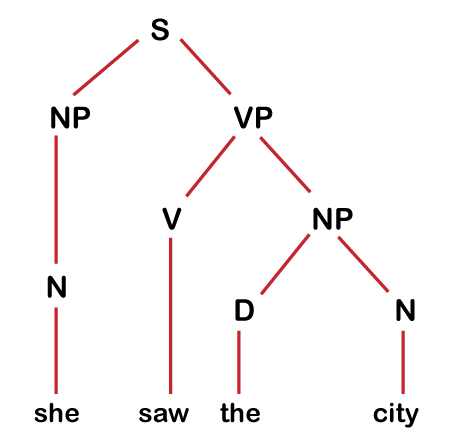
She saw the city.
This is a simple grammatical sentence, and we have to generate a syntax tree that represents its structure.
So, we want our AI system to be able to look at the sentence and figure out what the structure of the sentence is? Because to answer any question, AI system should know the structure, like if we ask AI what did she see? Then, AI should answer "City," so, for this, AI needs some understanding.
In the above example, each of the words in a sentence will be called terminal symbols, and each of the words in the sentence will be associated with the non-terminal symbols like N, V, and D etc.
N -------- She
V-------- saw
D-------- the
N-------- city
We assign each word a part of the speech. In the above example, "She" and "city" are Nouns. We have marked them as N. "Saw" is a verb, is marked as V. And, "the" is the determiner, which marks the noun as definite or indefinite, so we marked it as D. Now, the above sentence can now be written as
N V D N
To translate these non-terminal symbols into terminal symbols, we have some rewriting rules, which are:
N= she| city| car| Harry……..
D= the| a| an|………………..
V= saw| ate| walked|………..
P= to | on| over|……………..
ADJ= blue| busy| old|……….
N stands for Noun, V for the verb, D for determiner, P for Preposition, ADJ for adjectives.
So, when we are defining the structure of any language, we define these types of rules. But here in the above rules, we are dealing with single nouns and single verbs, but when we deal with the multiple words which operate as a noun or verb, we call them noun phrases and verb phrases. So, to deal with those type of sentences, we need to introduce more rules, which means we need more non-terminal symbols like
NP= N|DN
It means that a noun phrase can be a noun or a determiner followed by a noun.
VP= V| V NP
It means that a verb phrase is just a verb or a verb followed by a noun phrase.
S= NP| VP
S is a sentence which can be a noun phrase or verb phrase. Likewise, we can have multiple rules to define the structure of the sentence. And, using the structure, we can construct the sentence which looks like this:
NLTK: Natural Language Toolkit
For the idea discussed in Context-free Grammar, many libraries have been written to implement it. In the case of python, one such library is "nltk" (Natural Language Toolkit). This library provides a wide variety of functions and classes which deal with natural language. One of the nltk library functions is "ChartParser," which can parse the context-free grammar and construct the syntax tree for it.
Python Code:
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
AP -> A | A AP
NP -> N | D NP | AP NP | N PP
PP -> P NP
VP -> V | V NP | V NP PP
A -> "big" | "blue" | "small" | "dry" | "wide"
D -> "the" | "a" | "an"
N -> "she" | "city" | "car" | "street" | "dog" | "binoculars"
P -> "on" | "over" | "before" | "below" | "with"
V -> "saw" | "walked"
""")
parser = nltk.ChartParser(grammar)
sentence = input("Sentence: ").split()
try:
for tree in parser.parse(sentence):
tree.pretty_print()
tree.draw()
break
except ValueError:
print("No parse tree possible.")
Explanation:
- First, we have imported the nltk library.
- We have defined the set of rules in which we have defined some terminal and non-terminal words inside the variable named grammar.
- Then, we have defined a variable named "parser," in which we have used the ChartParser function from the nltk library, which has the ability to parse the sentence and construct the syntax tree.
- The next program will ask for input, and .split will split all the spaces. So, we get each of the individual words and save it in a variable called a sentence.
- Then, we have taken the sentence as input and printed the syntax tree.
For example, the input sentence is: "she saw a big dog on the street."
Output:
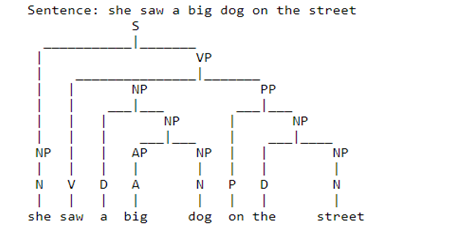
The nltk's Algorithm and this particular Algorithm has the ability to find the different structures and to extract some sort of useful meaning from the sentence as well.
n-gram
A context-free grammar is likely to deal with the sentences having single verbs and nouns. So, we need a system to understand how the words' sequence are likely to relate to each other in terms of the actual words themselves.
For example Context-free grammar is likely to understand and generate sentences like "I ate a banana."
But, sentences like "I ate a blue car" seem syntactically correct according to the context-free grammar rules, but it doesn't make any sense. So, we need our AI to encapsulate the idea that certain words are more or less likely than others. So to deal with that, we introduce the notion of the n-gram.
In n-gram, we refer to some sequence of n items inside our text, and those items can take different forms.
- Character n-gram- It is a contiguous sequence of n characters from a sample text, like three characters in a row or four characters.
- Word n-gram- It is a contiguous sequence of n words from a sample of text. We can choose any value of n. So when n is 1, a single word or single character and based on value of n we can classify them further, which are:
- Unigram- It is a contiguous sequence of 1 item from a sample of text.
- Bigram- It is a contiguous sequence of 2 items from a sample of text.
- Trigram- It is a contiguous sequence of 3 items from the sample of text.
“How often have I said to you that when you have eliminated the impossible whatever remains, however improbable, must be the truth?”
In the above example, if we have to take the sequence of three words so the first trigram would be "How often have" the second trigram would be "often have I," the third trigram would be "have I said" and so on.
And, extracting the trigrams and bigrams etc., are often helpful while analyzing a lot of text. So it's not meant to analyze the whole text at one time. Instead, we segment that whole text into segments through which we can begin to do some analysis as our AI might have never seen this entire sentence before, but it has probably seen the trigram or bigram before. So segments make the analysis easy for AI.
Tokenization
Tokenization is a task where we extract the sequence. Basically we need to take our input and somehow separate it into pieces, also known as tokens. So sometimes tokens can be words and sometimes tokens can be sentences and task is called word tokenization and sentence tokenization respectively.
Text is split into words based on punctuation like period, space, and comma etc. Sometimes separating by punctuation is not perfect like in the case of "Mr. Holmes," and we face more challenges like in the case of "o'clock" and hyphens, e.g., "pearl-grey." These are the things that our Algorithm has to decide. There are always some rules that we can use like we know that in "Mr. Holmes," the first period is not the ending of the sentence, so we can encode the rules in our AI system so that it can do tokenization the way we want.
Once we have the ability to tokenize a particular passage from there, we can begin to extract the n-grams and also check the most popular n-grams.
import nltk data = "Natural language is a central part of our day to day life, and it's so interesting to work on any problem related to languages." nltk_output = nltk.word_tokenize(data) print(nltk_output)
Output:

In the above program, we have used the word_tokenized function from nltk to tokenize the data.
import nltk
from nltk.util import ngrams
# Function to generate n-grams from sentences.
def extract_ngrams(data, num):
n_grams = ngrams(nltk.word_tokenize(data), num)
return [ ' '.join(grams) for grams in n_grams]
data = 'A class is a blueprint for the object.'
print("1-gram: ", extract_ngrams(data, 1))
print("2-gram: ", extract_ngrams(data, 2))
print("3-gram: ", extract_ngrams(data, 3))
print("4-gram: ", extract_ngrams(data, 4))
Output:

In above program we have imported ngrams from nltk library and created a function to generate the n-grams and printed unigrams, bigrams, trigrams and so on.
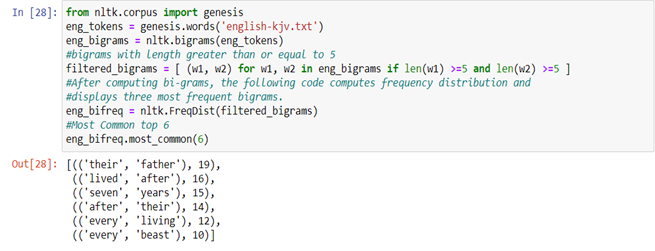
And the next program is to calculate the most frequent bigrams in the text file named as English-KJV.text then computed bigrams by using bigrams function from nltk.
from nltk.corpus import genesis
eng_tokens = genesis.words('english-kjv.txt')
eng_bigrams = nltk.bigrams(eng_tokens)
#bigrams with length greater than or equal to 5
filtered_bigrams = [ (w1, w2) for w1, w2 in eng_bigrams if len(w1) >=5 and len(w2) >=5]
#After computing bi-grams, the following code computes frequency distribution and displays three most frequent bigrams.
eng_bifreq = nltk.FreqDist(filtered_bigrams)
#Most Common top 6
eng_bifreq.most_common(6)
Output:
Text Categorization
Text categorization is a classification problem in which we take some text and categorize them into different classes. Every time we have some sample of text and we have to put it inside some category.
For Example:
- Spam Detection- Given email belongs to an Inbox or Spam folder. We are able to that by looking at the text and do some sort of analysis on that text to be able to draw some conclusions.
- Sentiment Analysis- Given sample of text belongs to a positive sentiment or negative sentiment.
Bag-of-Words Model
Bag-of-Words Model is the approach where we think about the language and model a sample of text not by caring about its structure but just caring about the unordered collection of words which are there inside of a sample. So basically we don’t pay attention to the sequence of the words or what noun goes with what adjective, we only care about the words.
Let’s analyze few sentences:
“My son loved it! It was fun!”
“Table broke after a few days.”
“This was one of the best games I’ve played in a long time.”
“This is kind of cheap and flimsy, not worth it.”
After analyzing only on the words in every sentence and ignoring the grammar, we can conclude that sentences 1 and 3 are positive because they contain the words like “loved”, “fun”, and “best” and sentences 2 and 4 are negative because they contain words like “broke”, “cheap”, and “flimsy”.
This approach tends to work in classifying the text like positive or negative sentiments. There are different approaches to do classification, but in Natural Language Processing most popular is Naïve Bayes.
Naive Bayes Classifier
Naïve Bayes Classifiers are based on Bayes Theorem. It is the collection of classification algorithm. It is the family of Algorithm where all the Algorithm share a common principle that every pair of feature which is classified is independent of each other.
Bayes Theorem
Bayes theorem gives the formula also known as Bayes formula is used to calculate the conditional probability of events. It is expressed as:
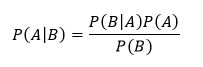
Where:
- P(A|B) – The probability of event A occurring given event B has occurred.
- P (B|A)
– The probability of event B occurring, given event A has occurred.
P (A) – The probability of event A.
- P (B)
? The probability of event B.
For example for sentiment analysis, we would use the above formula to find the conditional probability i.e.
P (sentiment | text)
For example, P (positive | “my son loved it”)
First we will start by tokenizing the input in such a way that we get
P (positive | “my”, “son”, “loved”, “it”)
Now, after applying Bayes rule, we get the following expression:
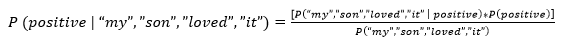
This expression will give a precise answer of the probability.
Now, in the above examples, we can see that probability of denominator will remain unchanged as it doesn't contain any positive or negative. So we can say that P is proportional only to the numerator.
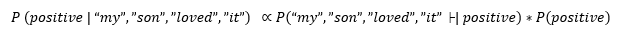
For now we can ignore the denominator, and now we know what the probability is proportional to, and at the end, we can normalize the probability distribution and make sure that probability distribution ultimately sums up to 1.
Now, using the rule of joint probability, we can simplify the above equation as:
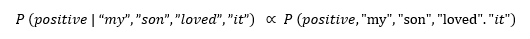
Now the question is that How do we calculate the Joint Probability.
We can calculate the Joint Probability by multiplying all of the conditional probabilities.
Now we can convert the above expression to.
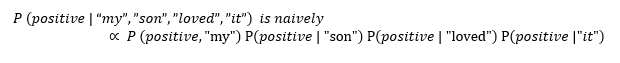
Now, we can see that calculations become complex, but we can calculate this probability when we have some data available to us, and this is what a Natural Language Processing is about, i.e., analyzing data. If we have data with a bunch of reviews labeled as positive or negative, then we will be able to calculate the probability of positive and negative terms, respectively.
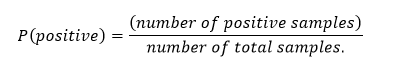
And,
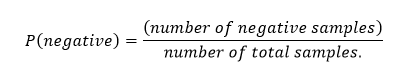
For example,
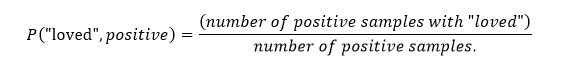
Suppose we have this data available to us is given in the tables below:
| Positive | Negative |
| 0.49 | 0.51 |
Above table shows the total positive and total negative probabilities.
And, table below shows the positive and negative probabilities of all the words, that how many times a word used is in a positive or negative sentence.
| Positive | Negative | |
| My | 0.30 | 0.20 |
| son | 0.01 | 0.02 |
| loved | 0.32 | 0.08 |
| it | 0.30 | 0.40 |
And, now we have to calculate whether the sentence "My son love it" is positive or negative so, for that we will have to calculate the probability of the expressions given below;
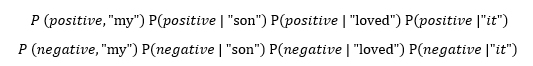
P (positive | “my”, “son”, “loved”, “it”) = 0.49(0.30×0.01×0.32×0.30) = 0.00014112
P (negative | “my”, “son”, “loved”, “it”) = 0.51(0.20×0.02×0.08×0.40) = 0.00006528
As we can see above, negative and positive probability values doesn't make sense, so we need to normalize them by dividing each value by sum of both positive and negative.
P (positive | “my”, “son”, “loved”, “it”) = 0.6837
P (negative | “my”, “son”, “loved”, “it”) = 0.3163
Now we can say that it is a positive sentence with 68.37% probability.
One problem with this approach is that if any word has never appeared in a certain type of sentence, then it became zero. Suppose none of the positive sentence in our data had "son" Then its Probability would be zero, and after calculating the final P(positive) it would also come zero. So to avoid these kind of scenario, there are different methods which are:
- Additive Smoothing- In Additive Smoothing, we add a value 'a' to every value in the data available.
- Laplace Smoothing- In Laplace Smoothing, we add 1 to every value in our distribution.
These are the approaches we can use while applying Naïve Bayes. Given enough train data, we can train our AI to be able to look at natural language, human words and categorize them accordingly.