Machine Learning Clustering Algorithm
Introduction to ML Clustering Algorithm
Clustering falls under unsupervised learning methods. In this, the machine is provided with a set of unlabeled data, and the machine is required to extract the structure from the data from its own, without any external supervision.
It searches for similar patterns in the dataset and then forms a cluster of such samples by similar grouping attributes. In other words, Clustering is a process of grouping related data samples, such that data points in one group are of the same kind but are different from the data points in another group. An assumption is made, and based on that similarity of datapoints is constituted.
An example of a cluster system is given below, to get more clarity about the concept of Clustering;
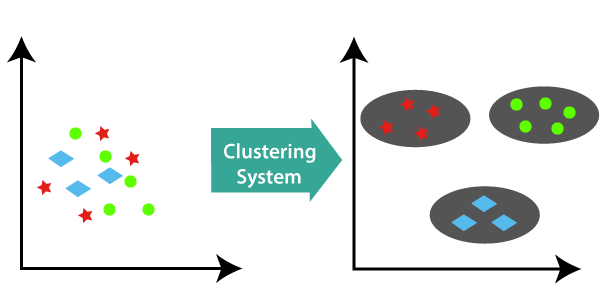
Different Methods of Cluster Formation
There are several methods for cluster formation that are given below;
1. Density-Based
In density-based methods, the clusters are built as a dense region having a relationship. They result in excellent accuracy and facilitate in merging two clusters. Its examples are DBSCAN (Density-Based Spatial Clustering of Applications with Noise), OPTICS (Ordering Points to Identify Clustering Structures), etc.
2. Hierarchical Based
In these methods, the clusters are constructed as a tree-like structure. There are two types of approaches, such as the Bottom-Up approach (Agglomerative) and the Top-Down approach (Divisive). For example, Clustering using Representatives (CURE), Balanced iterative Reducing Clustering using Hierarchies (BIRCH), etc.
3. Partitioning
In these methods, the clusters are made by splitting the samples into K clusters, such that the no of splits will be equal to the no of clusters. Examples are: K-means Clustering and CLARANS (Clustering Large Applications based on randomized Search)
4. Grid
In these methods, clusters are molded as a grid. The clustering functions performed on grids are faster and are independent of datapoints. Examples are Statistical Information Grid (STING), Clustering in Quest (CLIQUE).
Application of Clustering
- For reducing and compressing data: The concept of Clustering is extensively used in the field image processing as well as in vector quantization for data reduction, compression, and summarization.
- Intermediary step for Data mining steps: Since cluster serves well in summarizing the data for classification, hypothesis generation, and testing, it proves to be an intermediate step for data mining tasks as well.
- Biology: It works well in the classification of biological anatomies like plants and animals.
- Insurance: It is used to keep track of customers and their policies while recognizing the frauds.
- Study of Earthquake: It may help in grouping earthquake affected areas to ascertain dangerous zones.
- Social Network Analysis: Based on the concept of Clustering, it helps in generating a series of images, videos, and audios.