Why we need Distributed Database Management System
Assuming there is a very strong single machine having properties like:
- Heaps of memory.
- Gigantic measure of dependable stockpiling with very quick I/O.
- Incredible handling rate and processing power (10s, 100s and might be great many centers).
- Incredibly solid and issue open minded. The machine ought to generally be accessible; ready with zero personal time.
- Rapid systems administration framework associating clients for low inactivity client server correspondence. The organization won't ever go down.
- What's more, whatever other thing that will add to the registering force of this machine.
In the event that we truly have a framework like this, we don't have to convey a product in a disseminated framework. On the off chance that ages down the line, such a framework is created there won't be any need to plan and foster dispersed frameworks. A solitary PC will take care of the multitude of issues like an enchanted wand.
The issue is such a framework doesn't exist, and to that end we run into plan issues like accessibility, adaptation to internal failure, throughput, dormancy, versatility, unwavering quality, network parcels, information consistency, information dissemination, replication and a great many different issues that could end up being a major snag in the progress of business. Until the mysterious framework is created, these issues can't be addressed on a solitary machine.
We can begin with a solitary machine, and scale it in an upward direction by adding more assets (figuring power, memory, equipment and so on), yet all things considered, eventually vertical scaling by adding strong (and furthermore costly) programming/equipment won't end up being financially savvy.
Also, a solitary machine is reasonable going to be a bottleneck in throughput and adaptability. It will obviously be a weak link, and in this manner the framework will not actually be issue open minded.
Consequently the product is created in a manner to such an extent that it traverses various hubs (modest ware equipment with sensible assets). At the end of the day, we scale out evenly and foster a conveyed framework. Here we do things like: recreating information to different hubs for more prominent accessibility, more hubs additionally implies seriously registering power, no weak link, more noteworthy accessibility and so forth and so on We then, at that point, need to contemplate keeping up with information consistency or compromising it with another foundational property.
The point I am attempting to make is that we foster a dispersed framework to address the objectives that can't be accomplished with a solitary PC (essentially in this day and age). However, indeed such issues become more perplexing and testing to settle in a conveyed framework, and to that end we really want to concentrate on disseminated calculations, notable issues, arrangements that are normally viewed as when architecting any circulated framework.
There ought not be such thing as "OK here are the explanations behind fostering a disseminated document framework", and here are the purposes behind fostering a circulated information base".
Obviously record framework and information base tackle different reason and have their own arrangement of highlights and uses, yet the major purposes behind creating them in a dispersed way are same.
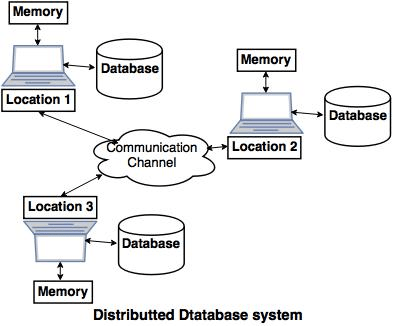
Benefits of Distributed information base
Disseminated information bases fundamentally give us the upsides of appropriated processing to the data set administration area. Essentially, we can characterize a Distributed information base as an assortment of numerous interrelated data sets conveyed over a PC organization and an appropriated data set administration framework as a product framework that fundamentally deals with a dispersed data set while making the dissemination straightforward to the client.
Conveyed data set administration essentially proposed for the different explanation from hierarchical decentralization and efficient handling to more prominent independence. A portion of these benefits are as per the following:
1. The executives of information with various degree of straightforwardness -
Preferably, a data set ought to be conveyance straightforward in the feeling of concealing the subtleties of where each record is actually put away inside the framework. The accompanying sorts of transparencies are fundamentally conceivable in the conveyed data set framework:
- Network straightforwardness:
This fundamentally alludes to the opportunity for the client from the functional subtleties of the organization. These are of two sorts Location and naming straightforwardness.
- Replication transparencies:
It essentially made client uninformed about the presence of duplicates as we realize that duplicates of information might be put away at different destinations for better accessibility execution and dependability.
- Discontinuity straightforwardness:
It essentially made client uninformed about the presence of sections it could be the upward piece or flat fracture.
2. Expanded Reliability and accessibility -
Unwavering quality is fundamentally characterized as the likelihood that a framework is running at a specific time though Availability is characterized as the likelihood that the framework is constantly accessible during a period span. Whenever the information and DBMS programming are circulated more than a few destinations one site might fall flat while different locales proceed to work and we can't get to the information that exist at the bombed site and this fundamentally prompts improvement in unwavering quality and accessibility.
3. More straightforward Expansion -
In a conveyed climate extension of the framework as far as adding more information, expanding data set estimates, or adding more information, expanding data set measures or adding more processor is a lot more straightforward.
4. Further developed Performance -
We can accomplish interquery and intraquery parallelism by executing numerous inquiries at various locales by separating an inquiry into various subqueries that fundamentally executes in equal which essentially prompts improvement in execution.