Simple hash() function in C
Introduction
In this context, we briefly discuss HASH FUNCTION, HASHING or HASH TABLE in C. It is a function used to map data and mapped arbitrary sizes to the fixed-size values.
The most crucial topic in hashing is “SEARCHING”, which determines the time complexity. It reduce time complexity. The data is stored in the array format in the
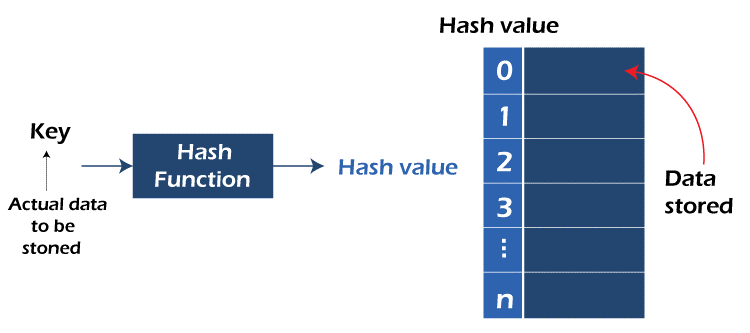
hash table. It is a faster technique and also very useful. This table held the data in an associative manner.
In this above diagram, we have seen that the actual data is to be stored in the hash key. The key value goes to the hash function. The hash function moved towards the hash value.
The hash value stored in the hash table.
By this diagram we can see that how hash function is works in C language.
What is Hash Function?
In the hash function, H accepted a variable-length block of input known as M and produced the fixed size of the hash value. That value is represented as:
h = H (M)
The Hash function uses the operation of the constant time. The function is converted a significant number into a small integer form. This function is to store values. It is also used to recover the values from the hash table. This is also used as the address in the hash table.
What are the 3 main properties of the HASH FUNCTION ?
There are three main properties of the secure hash function: Pre-image resistance, Second pre-image resistance, and collision resistance.
What is meant by the good hash function in C ?
A hash function should have the following properties. This properties is determine whether the function is good or bad. The properties are :
- In this function, Keys are should be uniformly distributed.
- The efficiency of this function should be computable.
Why we use the hash function?
The Hash function uses to store the values. It reduces values from a database because it helps accelerate the process.
Types of hash function in C
The types of hash function in C language are :
- Division Method
- Mid Square Method
- Digit Folding Method
- Multiplication Method
Now we are briefly discuss in these method :
1.Division Method : This method is the most accessible and straightforward method to generate the hash value. The hash function depends upon the reminder of a division; if the hash function divides the value X by M, then the remainder is obtained.
Formula of direct method:
h (x) = x mod M
here,
x is the value of key
M is the size of the hash table
M is the prime number because it is decided that the keys value are uniformly distributed.
Example :
If the value,
x = 1234
M = 4
h (1234) = 1234 mod 4
=2
Advantage :
- This method is a speedy operation.
- This method requires only a single division operation and is suitable for the value M.
Disadvantage :
- We need to take extra care in choosing the value M.
- The division method leads to poor performance.
2. Mid Square Method : In the mid-square method, the middle part of the square element takes as the index. It is a perfect and valuable hashing method. In this method, two steps require to compare the hash value. The steps are:
Square the value of the key. Which means X2. Exact the middle r digit as the hash value. The value of the r is to be decided based on the size of the table value.
Formula :
h (X) = h (X * X)
here , X is the key value .
Example :
X = 50
X * X = 50 * 50
=2500
h (X) = h (X * X)
h (50) = 50
\The hash value is 6Advantage :
- In this method, the result is not dominated by the distribution of the top or bottom digit of the main key value.
- The performance is good in this method.
Disadvantage :
- In this method, if the size of the key is significant, then its square will double the number of digits.
- In the mod square method, there is a collision present.
3. Digit Folding Method : The digit folding method is done in two steps:
In this method, the value of key or critical X divides into several parts that are X1, X2, X3, X4………Xn.
Each part contains the same number of digits except the last part because it contains less number of digits than the other part. Then, each part is added, and the hash value we find by ignoring the last carry.
Formula :
X = the key value
X = X1 ,X2, X3, X4 ……… Xn
Sum = X1 + X2 + X3 + X4 + ……… + Xn
h(X) = SumHere,
Sum is find by adding the parts of key X.
Example :
X = 170316
X1 = 17 ,X2 = 03, X3 = 16
Sum = X1 + X2 + X3
=17+03+16
=36
h (X) = 36
4. Multiplication Method : The multiplication method is done by following steps At first, choose a value Y. The value of Y is 0<Y<1.
The key value is X.
Multiply X with Y and extract the functional part from XY.
Then multiply the value of XY with the value of hash table M. The hash value finds by taking the resulting floor in step (iii).
Formula :
h (X) = floor (M(XY mod 1 ))
here,
- X is the Key value
- K is the choose value or constant value
- M is the size or value of the hash table
Example :
X = 1256
Y = 0.523
M = 10
h (1256) = floor (10(1256 * 0.523 mod 1))
= floor (10(656.888 mod 1))
= floor (10(0.888))
= floor (8.88)
= 8
Advantage: The multiplication method is easy to use. This method can work at any value between 0 to 1. The user can easily understand this method.
Disadvantage: The multiplication method depends on the size of the table value. The table value should be in the power of the two, which means table value = 2n [n = 1, 2, 3 …..].Then the whole process of computing the index using hashing value is too fast.
Collision resolution Technique : Collision is storage or condition when two or more data items arrive in the exact location. The collision resolution techniques are mainly two types.
The techniques are :
- Chaining - This is also known as Open hashing.
- Open addressing – This is also known as Close hashing.
We want to make an external chain. This technique is also known as open hashing because the provided space, and open space, are used in this hashing. This method gives some chains or boxes for the record that needs two-element entries.
Example – 24, 19, 32, 44, 51 with the hash table size 6
Hash (key) = 24 % 6 = 0
Hash (key) = 19 % 6 = 1
Hash (key) = 32 % 6 = 2
Hash (key) = 44 % 6 = 2
Hash (key) = 51 % 6 = 3
| 0 | 24 |
| 1 | 19 |
| 2 | 32 |
| 3 | 51 |
| 4 | Null |
| 5 | Null |
Table no two is already packed with the data 32; that’s why a chain connects 44 in table 2. This is the method of chaining.
Open Addressing : Open addressing means the provided space in the hash table utilizes first. This is also known as closed hashing. Open addressing is divided into three parts – (i) Linear Probing, (ii) Quadratic Probing, and (iii) Double Hashing.
1.Linear Probing –
The Linear Probing method is another technique for collision resolution. In this method, we don’t space the 2 data in one table. By this method, we placed the second data in the following empty table or the space. But if no open space is founded, then it leads to clustering. Then this problem is also known as the clustering problem.
Example - 24, 19, 32, 44 with the hash table size 6
Hash (key) = 24 % 6 = 0
Hash (key) = 19 % 6 = 1
Hash (key) = 32 % 6 = 2
Hash (key) = 44 % 6 = 2
| 0 | 24 |
| 1 | 19 |
| 2 | 32 |
| 3 | 44 |
| 4 | Null |
| 5 | Null |
In this diagram, the data 32 and 44 are wanted to place in table no 2, but this method doesn’t allow it. So 32 set table no 2 and 44 sets next empty space, i.e. table no 3.
2.Quadratic Probing –
This method is used to solve the problem which is arrived at by linear probing. The Quadratic Probing method resolves the problem of clustering. The hash function with the hash key is calculated as :
hash (key) = (hash (key) +x*x ) % (size of the hash table)
[x = 1, 2, 3, 4,…….]
Example –24, 19, 32, 44 with the hash table size 6
Hash (key) = 24 % 6 = 0
Hash (key) = 19 % 6 = 1
Hash (key) = 32 % 6 = 2
Hash (key) = 44 % 6 = 2
| 0 | 24 |
| 1 | 19 |
| 2 | 32 |
| 3 | 44 |
| 4 | Null |
| 5 | Null |
This diagram shows that 24, 19 and 32 are easily placed in the hash table. But in the case of 44, it has the same hash key value as 32. So as per this method, we calculate the Hash key value of 44.
hash (44) = (44+ (1*1)) % 6 = 3
so the hash key value of 44 is 3. Now we placed 44 in index number 3.
Double Hashing –
Double means two hash functions we can use here. Using two hash functions, we can resolve the collision problem. Two steps do this method : Calculated just using a simple division method. This must not be equal to zero, and entries must be probed.
Hash (key)1 = Key % size of the hash table
Hash (key)2 = p – (key mod p) [p is Prime Number < size of the hash table]
Example – 20, 34, 45, 70 with table size 11
Hash (key) = 20 % 11 = 9
Hash (key) = 34 % 11 = 1
Hash (key) = 45 % 11 = 1
Hash (key) = 70 % 11 = 4
| 0 | NULL |
| 1 | 34 |
| 2 | NULL |
| 3 | NULL |
| 4 | 45 |
| 5 | NULL |
| 6 | 70 |
| 7 | NULL |
| 8 | NULL |
| 9 | 20 |
| 10 | NULL |
R1(k) = k mod 11
R2(k) = 8 – ( k mod 8 )
In this diagram , the element 45 can be placed using hash 2(key) = 8 – (45 % 8) = 3
(R1(k) + R2(k)) mod 11
= 1 + 1*3 = 4
So, we place the element 45 in table number 4. Now the hash key value of 70 is 4 . But 45 is already stored in to table number 4 . The element 70 can be placed using hash2(key) = 8 – (70 % 8) = 2
(R1(k) + R2(k)) mod 11
= 4 + 2 = 6
So, we place the element 70 in table number 6.
Application of HASH FUNCTION
The hash function is used in programming languages like C, C++, Python, and Java script to implement objects. It is also used in disk-based data structure and database indexing. Hash is used in cryptography and password verification.
Advantage of HASH FUNCTION
The Hash function is more efficient and provides better synchronization than the data structure. It gives a time constant for searching, deletion, and insertion.
Disadvantage of HASH FUNCTION
Main disadvantage of the hash function is a collision. The Hash function also does not allow the null values.
Conclusion
Hashing is very efficient and effective for searching the data. It is a fast method. The hashing is better than any data structure.