Memory Layout of a Process in Operating System
The layout of the memory of a specific process is done so that the Operating system can easily access and perform given actions on the code or program at a particular instance. This way of organising the memory is done in multiple separate modules or components, which include the source code, the data, the stack, and the heap. These modules are organised in a particular memory layout inside the virtual address of the process. The layout of this memory can be different from the other, because of the operating system that we are working on.
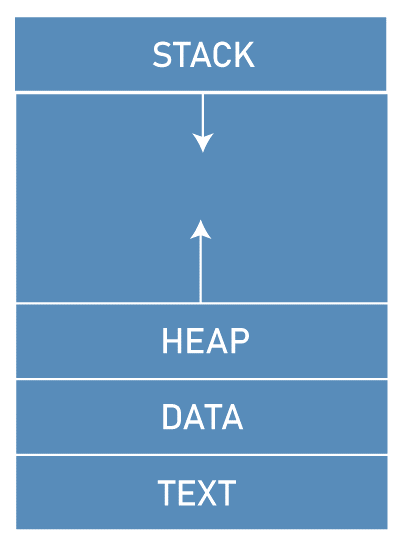
Different components sum up the memory layout. They are:
- Text segment
- Data segment
- Heap
- Stack
These individual components will make a proper layout and then helps in the execution of the code correctly.
1. Text segment
The text segment contains the source code which a user works on. This may contain a variety of text or code in the memory within the sections of the program. These contain the operations or commands that are executable. Since this is a memory space, the text segment will be placed at the bottom of the heap and stack. This is done to prevent the heap or stack from overflowing with the data which we enter.
Generally, the text segment is transferable, which means only a single copy of the data or code is enough in the memory which can be called and executed at any time. But the data or code in the text segment is limited only to readable types of data, and this is done to prevent overwriting additional instruction in the original data, which makes the data altered and ambiguous.
2. Data segment
The data segment basically consists of the global variables and the static variables from the code. This is the central portion of the address space of a program virtually. There are two types in the data segment.
- Initialised data segment: In this type of data segment, it contains only the initialised global and static variables from the code which are initialised by some specific values at the start of the program. The data segments are not specified only for read mode, because the data can be altered in this segment in the run time. The initialised data segment contains a designated space for the storage of the variables and other access specifiers from the program, which are used at the time of execution. Some of the initialised data include variables, integers, float values, arrays, etc.
- Uninitialized data segment: The uninitialized data segment is also called as bss, which is named after the block started by symbol. The data in this segment are initialised by the kernel of the operating system to 0 prior to the start of the program. This contains the global variables along with the static variables, and these variables are also set to 0.
This data segment will not store the variables with their initial values, which is done in the initialised data segment. This data segment helps reduce the size of the program by allocating the memory to the OS without redundancy of values.
3. Heap
The heap is a segment in this memory layout that is responsible for dynamic memory allocation. This is done during the program execution; this uses the allocated memory to fulfil the needs. The heap provides the extensible and resizable type of memory for storing the data, objects, and arrays, strings. This allows the program to request the memory at the run time of the code, by using the functions like malloc, and deallocate. These are used to assign dynamic memory in the code for better execution. These functions are used in languages such as C and C++. This enables the flexibility in the code and adds the functionality of the heap data structure.
This provides better memory arrangements and accessing the memory is made easy, reducing the time and resources. The heap segment is a valuable and a better way to access the memory for dynamic memory management.
4. Stack
The stack is also one of the segments in the memory layout, which is used primarily for managing the function calls in the source code. The stack is automatically managed by the compiler at the runtime environment, and this makes sure that the memory that is being allocated is again deallocated correctly at the right time. The stack pointer, is a very useful register in this segment that helps keep the track of the memory being transferred. The stack follows a LIFO manner which means Last in First out. This means that the stack will delete the data which is recently entered or is last entered among all. This follows two operations, Push and Pop, which means removing and entering the data, respectively.
Because of a fixed memory size, this defines the start of the program. If there are more push operations, then there is a chance of stack overflow, which results in data loss. This ultimately results in system crashes and many more. It is vital to keep a track of the data that is being allocated to the stack as it is of a fixed size.