What is Context Switching
Context Switching is the switching of CPU from one process to another process. Context switching means storing the process state so that we can reload the process when needed, and the execution of the process can be resumed from the same point later. Context Switching is the characteristic of a multitasking operating system. In context switching, one CPU can be shared among several processes. In other words, context switching is the mechanism that permits a single CPU to handle several threads or processes without the need for extra processors.
In context switching, processes are switched so quickly that the user gets the myth that all processes are running simultaneously.
But in the process of context switching, there are lots of steps that we need to follow. We cannot directly change or switch the process from running state to ready state. It is mandatory to save the context of that process. If we do not save the context of the process, while again executing the process, we need to start its execution from the beginning. In reality, the process continues from that state, where the CPU left the process in its previous execution. So, it is required to save the context of the process before placing some other process in the running state. Context means data of CPU registers and program counter anytime.
Context Switching Triggers
The context switching triggers are:
- Interrupts
- Multitasking
- Kernel/user switch
Interrupts: - We require context switching if there is an interruption of CPU to get data from the disk read.
Multitasking: - If the CPU has to move processes in and out of memory so that it can run more than one operation.
Kernel/user switch: - We use kernel/user switch if we require switching between the user mode to the kernel mode.
Steps Involved in Context Switching
With the help of the below figure, we describe the procedure of context switching between the processes, which are P1 and P2.
We can see in the following figure that initially, the P1 process is in running state, and the P2 process is in the ready state. If there occurs some interruption, then it is required to change the state of the P1 process from running to the ready state. When the context of the process P1 is saved, then change the state of the P2 process from ready to the running state.
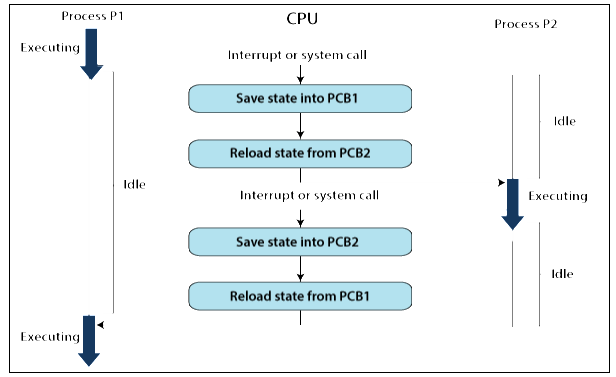
There are various steps which are involved in the context switching:
- The process P1 context, which is in the running state, will be stored in PCB (Program Control Block). That is called PCB1.
- Next, PCB1 is transferred to the appropriate queue, i.e., the I/O queue, ready queue, and the waiting queue.
- Then from the ready queue, we choose the new process which is to be executed i.e., the process P2.
- Next, we update the PCB (Program Control Block) of the P2 process called PCB2. It includes switching the process state from one to another (ready, blocked, suspend, or exit). If the CPU previously executed process P2, then we get the location of the last executed process so that we can again proceed with the P2 process execution.
- In the same manner, if we again need to execute the process P1, then the same procedure is followed.
Information stored in PCB (Program Control Block) for Context Switching
The information stored in PCB for context switching are:
- Program counter
- Information related Scheduling
- Accounting information
- Base and limits registers
- Changed state