Iswspace Function in C++
In this article, we will discuss the difference between the iswspace() function in C++ with its syntax and examples.
What is the iswspace() Function in C++?
The iswspace() function in C++ is essential for handling characters and manipulating strings. Depending on the current locale settings, it lets you determine whether a wide character qualifies as a whitespace character or not.
iswspace() takes a single argument, wint_t ch, representing the wide character to be checked. If the current locale determines that ch is a whitespace character, it returns a non-zero value. If not, it yields 0. This function is especially helpful when working with internationalized text and languages that might use different whitespace characters than the standard ASCII set.
Purpose of iswspace():
Identifying whitespace characters is essential for various tasks like:
- Trimming leading and trailing spaces from strings.
- Splitting strings based on whitespace delimiters.
- Counting the number of words in a string.
- Performing text alignment and formatting.
Certain tasks require the identification of whitespace characters, such as:
- Removing leading and trailing spaces from strings.
- Dividing strings according to the delimiters "&"
- Determining how many words are in a string.
- Carrying out formatting and text alignment.
By leveraging iswspace(), you can ensure accurate and consistent processing of whitespace characters regardless of the underlying locale.
The Header File and Function Signature for iswspace() in C++
Based on the current locale settings, the C++ iswspace() function determines if a given wide character is a whitespace character. The necessary header file and function signature are broken down as follows:
Syntax:
It has the following syntax:
int iswspace(wint_t wc);
Breakdown:
Return type: int: The function returns an integer value.
Argument:
wint_t wc: It is the wide-character to be checked. The wint_t type represents a wide character according to the current locale.
Header File:
#include <cwctype>
Explanation:
A collection of functions for categorizing wide characters according to their type and characteristics is available in the <cwctype> header file.
Access to the iswspace() function and other character classification functions, such as iswalnum() and iswdigit(), is made possible by including this header file.
Additional Notes:
If a character is deemed whitespace, the iswspace() function returns a non-zero value; otherwise, it returns a zero value.
Whitespace characters are categorized according to the current locale settings. You can use the setlocale() function to change the locale if necessary.
Example:
Let us take an example to demonstrate the usage of iswspace() function in C++:
#include <iostream>
#include <cwctype>
int main() {
wchar_t c = L'\n'; // Newline character
if (iswspace(c)) {
std::wcout << L"Character '" << c << L"' is a whitespace." << std::endl;
} else {
std::wcout << L"Character '" << c << L"' is not a whitespace." << std::endl;
}
return 0;
}
Output:
Character '
' is a whitespace.
Explanation:
This example determines whether the current locale views the newline character (L'\n') as whitespace.
Parameters: Clarifying the WCC Input for iswspace()
Wide character classification in C++ largely depends on the iswspace() function, which takes one argument, wc, very seriously. It is essential to comprehend the purpose and nature of this parameter to use iswspace() efficiently.
Dissecting the wc Parameter:
Format: wint_t: It means that wc is a wide character, meaning it can represent characters not in the standard ASCII set. It makes working with languages and symbols that might not have single-byte equivalents possible.
Part: The wide character that has to be checked for whitespace is stored in the wc Parameter. The character whose classification dictates the result is the central component of the function.
For instance, Assume you have a wide character L'€', which stands for the symbol for euros. You pass it to iswspace(), and the function checks if this symbol is considered whitespace in the current locale.
Demystifying the Return Value of iswspace() in C++
Wide character classification in C++ is greatly aided by the iswspace() function, but its usefulness depends on its return value. You must comprehend how this value operates to interpret the function's output and make wise code decisions.
Decoding the Return Value:
Type: int: iswspace() returns an integer value, providing a simple yet decisive indicator of the character's classification.
Interpretation:
Non-zero: According to the current locale settings, it indicates that the wide character passed as the wc Parameter is a whitespace character. It can be interpreted as a positive or "true" classification.
Zero: On the other hand, a zero return value means that the character is not considered a whitespace character in the current locale. It is equivalent to classifying something as "false" or negative.
Example:
wchar_t c1 = L'\t'; // Horizontal tab
wchar_t c2 = L'a'; // Letter
int result1 = iswspace(c1); // result1 is likely non-zero (true)
int result2 = iswspace(c2); // result2 is likely zero (false)
Wide Characters and Locale: A Harmonious Dance in C++
Narrow and wide are the two different character types available in C++. Wide characters extend their reach to encompass a wider range of symbols, including emojis, ideograms, and characters from various languages, while narrow characters are typically limited to the ASCII set and the basic Latin alphabets.
Wide Characters: A World Beyond ASCII
- Wide characters, denoted by the wchar_t type, can represent characters that single-byte ASCII does not limit due to their ability to accommodate a larger code point range.
- It allows C++ programs to interface with languages requiring multi-byte representations, such as Cyrillic, Arabic, and Chinese.
- Wide characters are necessary to ensure that your code can easily handle various text data types when localizing (l10n) and internationalizing (i18n).
Locale: Character Classification's Conductor
In C++, the locale concept is essential to interpreting and manipulating wide characters.
Character classification guidelines, collation order, and formatting conventions are just a few of the cultural and linguistic norms defined by a locale.
For example, the iswspace() function depends on the current locale to decide whether a wide character counts as whitespace.
It suggests that depending on the locale being used, how whitespace characters like tabs, newlines, and particular symbols are classified may vary.
Understanding the Interplay:
Assume you are determining whether the Euro (€) symbol is considered whitespace. More than likely, it is not classified as such in the English locale. However, it might be regarded as whitespace in a place where euros are widely accepted for formatting purposes.
The definition of whitespace in the locale determines this dynamic behaviour, emphasizing the importance of keeping the current context in mind when working with wide characters.
True Case: Identifying Whitespace Characters
Let us take an example to illustrate the iswspace() in C++.
#include <cwctype>
#include <iostream>
int main() {
wchar_t c1 = L'\t'; // Horizontal tab
wchar_t c2 = L'\n'; // Newline character
if (iswspace(c1)) {
std::cout << "Character '" << c1 << "' is a whitespace (tab)." << std::endl;
}
if (iswspace(c2)) {
std::cout << "Character '" << c2 << "' is a whitespace (newline)." << std::endl;
}
return 0;
}
Output:
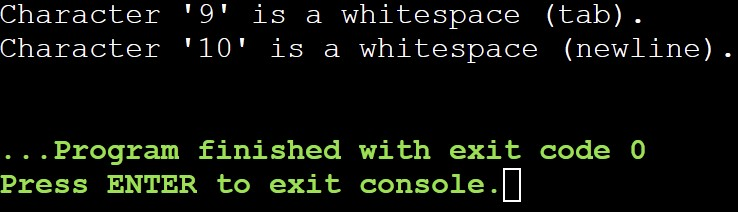
Explanation:
In this example, there are two wide characters—a tab and a newline are checked. The iswspace() function returns non-zero values (true), indicating that both are recognized as whitespace in most locales.
False Case: Classifying Non-Whitespace Characters
Let us take an example to illustrate the iswspace() with no-whitespace characters in C++.
#include <cwctype>
#include <iostream>
int main() {
wchar_t c1 = L'a'; // Letter
wchar_t c2 = L'€'; // Euro symbol
if (!iswspace(c1)) {
std::cout << "Character '" << c1 << "' is not a whitespace (letter)." << std::endl;
}
if (!iswspace(c2)) {
std::cout << "Character '" << c2 << "' is not a whitespace (Euro symbol)." << std::endl;
}
return 0;
}
Output:
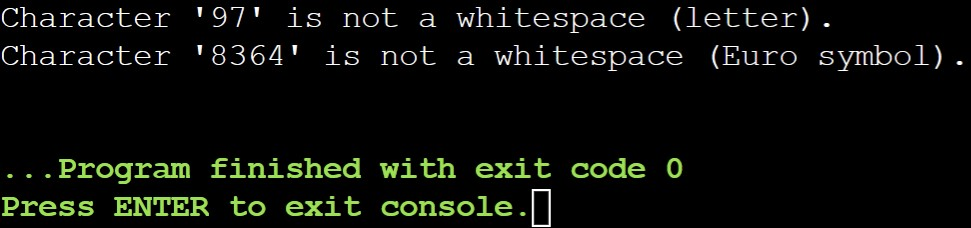
Explanation:
In this example, we assess two characters in this case: the Euro symbol and a letter. In the majority of places, neither is normally regarded as whitespace. As a result, both return zero (false) from the iswspace() function, indicating that they are not whitespace.
Bonus Example: Checking Whitespace in Different Locales
#include <cwctype>
#include <iostream>
#include <locale>
int main() {
// Set the locale to French (fr_FR)
std::setlocale(LC_ALL, "fr_FR");
wchar_t c = L'\r'; // Carriage return
if (iswspace(c)) {
std::cout << "Character '" << c << "' is a whitespace in French locale." << std::endl;
} else {
std::cout << "Character '" << c << "' is not a whitespace in French locale." << std::endl;
}
return 0;
}
Output:
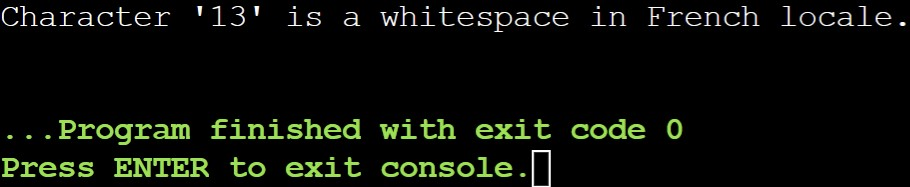
Explanation:
This example illustrates how the locale can affect how iswspace() behaves. As changing the locale to French demonstrates, the carriage return character is considered whitespace in this context, but it might not be in other locales.
The following instances demonstrate the flexibility of iswspace() and its potential applications:
- Recognize whitespace characters for formatting or string trimming, among other uses.
- In wide string operations, differentiate between whitespace characters and non-whitespace characters.
- Use locale awareness to modify your program's behaviour to suit various linguistic and cultural contexts.
Recall that the particular whitespace characters that iswspace() classify depend on the locale being used. By comprehending this dynamic and using the function effectively, you can improve the precision and cultural sensitivity with which your C++ programs handle various text data.