C++ Data Abstraction
Object-oriented programming (OOP) provides a number of characteristics that enable programmers to design programmes based on a variety of ideas, reducing errors and increasing program flexibility. The abstraction of data is one of the traits of object-oriented programming. This chapter explains how the C++ program implements the idea of data abstraction.
What does Abstraction mean :
Abstraction is an object-oriented programming method in which we hide implementation details from the user and only show the user the interface that is necessary.
Let's consider an Air Conditioner as an example. We have a remote control for controlling different AC operations such as start, stop, temperature increase/decrease, humidity control, and so on. We can control these operations simply by pressing a button, however these functions are performed using complicated logic on the inside.
As an end user, however, we are only exposed to the remote interface, not the implementation specifics of all of these services.
Abstraction is one of the main components of object-oriented programming, and it underpins practically all OOP solutions, i.e. the distinction of interface and execution details in the code.
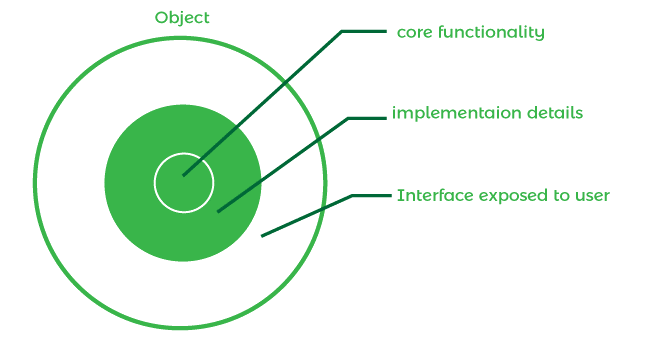
In this figure, we've shown an object and its contents as a graphical representation in the figure above. The basic functionality of this object is visible as the object's innermost layer, followed by the implementation details.
These two levels (albeit in most situations there is only one) are not visible to the outside world in OOP. The interface, the object's outermost layer, is the layer that allows the end user to access the object's capabilities.
They reveal adequate public methods to the external world to let users to play around with the object's functionality and data.
Simpler example can be when a state without understanding how the class is internally implemented. The pow() function, for example, is used to calculate a number's power without knowing the algorithm it employs.
Another relatable real life example of data abstraction can be when we consider the case of a man at the wheel of an automobile. The man only has a basic knowledge that on pressing the accelerator the car's speed will be increased and that applying the brakes will stop it, but he has totally no knowledge how about how the speed is increased by pressing the accelerators, nor does he have any clues regarding the car's inner mechanism or how the accelerator, brakes, and other controls are executed in the car.
In actuality, the fundamental functionality of sorting methods might change from library release to library release. Until and unless the interface remains the same, your function call will work perfectly.
As a result, any modifications made to the object's deepest levels are undetectable to an end user as long as the user's interface remains unchanged.
Types of Abstraction in C++ :
The Abstraction in C++ can be divided into mainly 2 categories, which are –
Data Abstraction –
The goal of data abstraction is to keep the information on the data hidden.
Control Abstraction -
The Control Abstraction mainly focusses on obfuscating the details of the implementation.
Abstraction Implementation in C++ :
C++ has a lot of abstraction support. Even the library functions we utilise in C++ may be thought of as an example of abstraction.
In C++, the implementation of abstraction may be represented as follows:
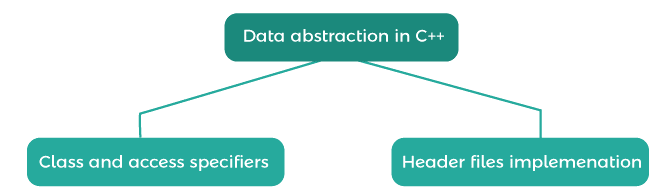
We may implement abstraction in C++ in two methods, as indicated in the diagram above:
Using Access Specifiers and Classes –
A C++ class having the access specifierspublic, private, and protected might be called an abstraction implementation.
The usage of access specifiers helps to manage the access allowed to class members, as we already know. Some members can be made private, making them not accessible by any external class. Some members can be marked as protected, making them only available to derived classes. Finally, we can make some members public, which will further allow them to be accessed from anywhere outside of the class.
We may use this concept to build abstraction in such a manner that the implementation details are concealed from the outside world using the private access specifier, while the interface is accessible using the public specifier.
As a result, we may construct abstraction in C++ by combining data and functions into a single unit and controlling access to this data and functions using access specifiers.
To show this, let's use the following example –
Example:
#include <iostream>
#include <string>
using namespace std;
class samples
{
int nmbr1,nmbr2;
void readNmbr(){
cout<<"Enter nmbr1 : "; cin>>nmbr1;
cout<<"\nEnter nmbr2 : "; cin>>nmbr2;
}
public:
void showSum()
{
readNmbr();
cout<<"\nSum of 2 nos. = "<<nmbr1+nmbr2<<endl;
}
};
int main()
{
samples s;
s.showSum();
}
Output :
Enter nmbr1 : 5
Enter nmbr2 : 11
Sum of 2 nos. = 16
Explanation :
In this example, we have an example class in the preceding code with two int variables, nmbr1 and nmbr2. It also contains the readNmbr and showSum methods. The class's nmbr1 and nmbr2 data elements, as well as the method readNmbr, are all private.
The class's showSum method is public. We construct a sample object in the main function and call showSum, which reads the two values and outputs their sum.
This is how the abstraction is put into practise. Only one function is visible to the public, while the rest of the data members and functions are hidden. Though this is simply an example of abstraction, we may have several degrees of abstraction in C++ when solving real-world situations.
Using the Implementation of Header Files –
In a C++ application, header files are used to import and utilise built - in functions. The #include directive is used to include header files inside our code.
Taking an example, the functions cin and cout, were used in the above code. We just have a basic understanding of how to utilise these functions and what parameters they require.
We don't know what happens in the backend when these functions are invoked or how the iostream header file implements them. C++ provides another another abstraction method.
We don't know how all of the functions that we import from the header files are implemented.
Here's another example of abstraction in action –
Example:
#include <iostream>
#include <string>
using namespace std;
class empl{
int emplno;
string names;
double income,basics,allowance;
double calcSalary(int emplno){
income = basics+allowance;
return income;
}
public:
empl(int emplno, string names,double basics,double allowance):
emplno(emplno),names(names),basics(basics),allowance(allowance){
calcSalary(emplno);
}
void show(){
cout<<"Emplno = "<<emplno<<"\tName = "<<names<<endl;
cout<<"Employee Income = "<<income;
}
};
int main()
{
empl emp(2,"Raj",17000,3456.78);
emp.show();
}
Output :
Emplno = 2 Name = Raj
Employee Income = 20456.78Explanation :
In the above example, we've created a class empl with private information such as an emplno, a names, and income information such as basics and allowance. We also build a private function called "calcSalary" that calculates the salary based on the basic pay and allowances.
A function is used to set up all of the data for a specific empl object. To compute the pay of the current employee, we use the method "calcSalary" from the function.
Then there's the "show" function, which shows the emplno, names, and income. We construct an empl object in the main function and call the show method.
The amount of abstraction that we have offered in this application is readily visible. By making them private, we've concealed all of the employee information as well as the calcSalary function from the user.
We have provided only one function show to the user, which provides all information about the empl object while also hiding aspects like as private data and how we compute the employee's compensation.
We won't have to update the display function in the future if we want to add new data or change the way the income is computed because of this. These modifications will go unnoticed by the user.
Benefits of Abstraction :
Some of the benefits of abstraction are described below –
- There is no requirement for the programmer to create low-level code.
- Abstraction guards against unauthorised usage and flaws in the internal implementation.
- Abstraction may reduce code duplication, reducing the need for the programmer to repeat the same activities.
- Abstraction encourages code reuse while also accurately categorising class data members.
- The programmer can alter the private information of the class architecture without impacting the outer layer activities, as long as the end-user is unaware of the changes.
Strategy for Design :
The interface and implementation sections of the code were separated through Data Abstraction. As a result, we should keep the implementation as is while developing the code. That is, the interface should be decoupled from the implementation. It's even useful for preventing code duplication.
As a result, we may reuse the code while changing the implementation, which helps safeguard the data from the external world.
Epilogue :
Abstraction is amongst the most fundamental ideas in OOP, and it is thoroughly implemented in C++. We can hide the program's implementation specifics behind abstraction and only disclose the details we wish to the outside world.
We may construct abstract data types and classes that operate as a skeleton for the coding solution over which a whole solution is developed utilising the abstraction notion. We'll get to know more about these types and classes as we continue through the OOP subjects further.