Hashing in C++
- Before understanding hashing, we need to know what the use of hashing is. Let us consider an example of a library which consists of many books.
- Having many books, searching for a particular book is difficult. To overcome this, we have to assign a key to every book, which can be used to know the book’s location.
- This technique is called hashing. Here it computes a unique key to every book instead of categorizing the books with subject, section, etc.
- We use a function to store the keys in a table. This function is called the “hash function”, and the table is called the “hashtable”.
- The hash function maps the key to the value, which helps fast access to elements. If the hash function is more efficient, then the mapping will be more efficient.
- For example, let us assume a hash function which is denoted by h(x), which maps the values “x” in the array at “x%10”.
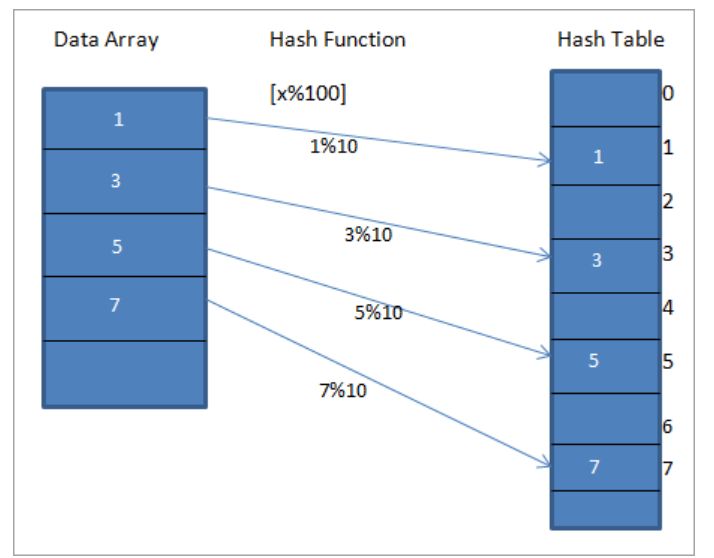
Hash Function
- The Hash function helps in mapping the key to the element, the higher efficiency of the hash function results in the efficiency of mapping.
- The hash function should have the following properties
- Easy to compute: The keys should be easily computed by the hash function.
- Less collision: There are chances of collision when the element tries to fit in a position already filled. The collision should be as minimum as possible. To reduce the collision, we use collision resolving techniques.
- Uniform distribution: Uniform distribution of data should be present so that it prevents clustering.
Hash Table
The hash table is a data structure which is used to store the elements of the data array that points to elements.
- Collision:
- When we map two or more keys to the same value, which results in a collision.
- We map the key to the value using hash function if the hash function map more key values to the same location, it causes the collision because the location is already occupied by another key value.
- C++ hash table:
- We use an array or linked lists to implement the hash table, In C++ we use the hash map feature where every entry is key-value pair.
- The hash function in c++ is usually unordered.
- In C++, we have stl, which is a standard template library which is defined by the< map > header.
/ / program to implement hash function
# include < bits/stdc++.h >
Using namespace std;
Class hashing {
int bucket;
/ / creating a pointer to an array containing buckets
list < int > *table;
public :
/ / defining a contructor
Hash ( int v );
/ / insert key in to hash table
void insertitem( int x );
/ / delete a key from hash table
void deleteitem ( int key );
int hashfunction ( int x );
{
return ( x % bucket );
}
void displayhash ( );
};
Hash : : Hash ( int b )
{
this -> bucket = b;
table = new list <int >[bucket];
}
Void Hash: : insertitem ( int key )
{
int index = hashfunction ( key );
table [ index ].push_back ( key );
}
Void Hash : : deleteitem (int key )
{
Int index = hashfunction ( key );
List < int > : : iterator I;
For ( int I = table [index].begin( ); i != table [ index ].end ( ); i++);
If ( *i == key )
break;
}
If ( i != table [index ].end ( ) )
table [ index ].erase ( i );
}
void Hash : : displayhash ( ) {
for ( int i =0 ; i < bucket ; i++)
{
cout << i;
for ( auto x : table [ i ] )
cout <<“ - - > “ << x;
cout << endl;
} }
/ / driver function
int main ( ) {
int a [ ] = { 15, 11,27, 8, 12 };
int n – sizeof (a)/ sizeof (a [0] );
/ / insert in to hash table
Hash h(7);
For ( int i = 0 ; i < n ; i++ )
h.insertitem( a[i] );
/ / delete from hash table
h.deleteitem ( 12 );
h.displayhash ( ) ;
return 0;
}
Output:
0
1 - - > 15 - - > 8
2
3
4 - - > 11
5
6 - - > 27Collision Resolving Techniques
- As mentioned, collision may occur when we try to map another element to an already mapped key.
- To avoid this collision, we use the collision resolving technique.
Open Hashing
- This is a commonly used technique to resolve the collision, which can be implemented using a linked list data structure. It is also called separate chaining.
- In this open hashing technique, we use linked list, the entry in a hash table.
- When the hash code is matched with the key, the element is entered into the linked list of the corresponding hash code.
- But when the collision occurs or when two or more have the same code, then another block is created connecting to the corresponding node using a linked list.
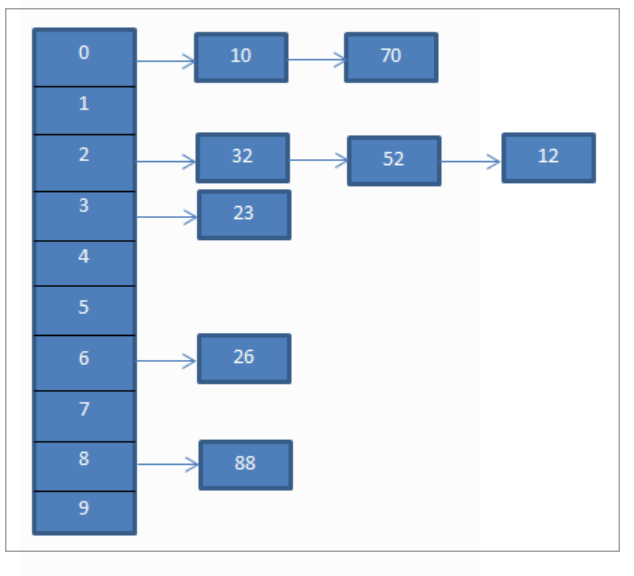
- In the above diagram, a mod function is used. when the two elements want to have the same hash code, which is achieved using a linked list.
Closed Hashing
- It is a collision resolving technique, which is also called linear probing.
- Here we don’t use any linked list all the data is stored in a hash table. When the hash code, which is mapped by key, is unoccupied, then there will be no problem. It will be occupied at that position.
- But if the hash code is occupied, then the key value is inserted in the next position, which is unoccupied.
- The function of linear probing is changed as follows:
Hash = Hash % Hashtablesize}
Hash = ( Hash + 1 ) % Hashtablesize
Hash = ( Hash + 2 ) % Hashtablesize
Hash = ( Hash + 3 ) % Hashtablesize
Hash = ( Hash + 4 ) % Hashtablesize
Quadratic Probing
- It is another way of collision resolving technique, which is similar to that of linear probing.
- The difference between linear probing and quadratic probing is the difference in interval used for probing.
- This technique, uses a quadratic function to find the distance for probing when the collision occurs.
- It reduces the primary clustering up to a certain level but does not reduce secondary clustering.
Double Hashing
- It is another way of collision resolving technique which is similar to that of linear probing.
- The difference between linear probing and quadratic probing is that it uses two hash functions for probing.
- It reduces both primary clustering and secondary clustering.
Applications of Hashing
Message digests:
- This is an application of hashing which uses cryptographic hash, Which is an application of cryptographic hash function, which produces output when it gets input which is not possible.
- We use this when we store any file on the cloud. We have to make sure that data should not accessed by any other party. So we use a cryptographic hash algorithm.
- SHA 256 is an example of a cryptographic hash algorithm.
Password verification:
- The cryptographic hash function is used for verification of passwords. The hash of the password is calculated when we enter the password, and the system will verify the password.
- Password is sent to a server for verification. This verification is done to ensure that no sniffing is there.
Compiler operation:
- The keywords are stored for languages when the compiler compiles the program.
- The hash table is used by the compiler to store the keywords in the form of a set.
- The examples of keyword are: if, else, for, return etc.
Data structures:
- The hash table is used in various programming languages. The main idea is to create a key and value which are mapped in a pair, which are also unique.
- We can see this implementation in C++ as an unordered set and unordered map, we use hash set and hash map in java language, it is also used as a dictionary in python.
Associative arrays:
- Hash table is used to implement associative arrays.
- The associative arrays in which the indices are of data type like strings or objects other than integers.
Rabin – Karp Algorithm:
- The Rabin-Karp algorithm is a famous application of hashing, which is used to find a pattern in a string.
- It is a string search algorithm. plagiarism is a practical application of rabin – Karp algorithm.
Game boards:
- It is used for games like chess or in tic- tac – toe, which is used to store the position.
- It is also used for graphics and database indexing.