Introduction to Huffman Coding
Huffman coding is a data compression technique that uses variable-length code to represent the characters in a file or data stream. The technique is named after its inventor, David A. Huffman, who published it in 1952. Huffman coding is a lossless compression technique, meaning no information is lost during the compression and decompression process. The main idea behind Huffman coding is to represent the characters that appear more frequently in the data with shorter codes while representing the characters that appear less frequently with longer codes.
Benefits of Huffman Coding
- One of the main benefits of Huffman coding is that it is a lossless compression technique. This means that the original data can be restored from the compressed data without any loss of information.
- Another benefit of Huffman coding is that it is very efficient, especially for files or data streams containing many repetitive characters. The technique can also compress data in real time, making it an ideal solution for streaming video and audio.
How does Huffman Coding Work?
The basic idea behind Huffman coding is to represent the characters in a file or data stream with a variable-length code.
- The first step in the process is to count the number of times each character appears in the data.
- The next step is to create a binary tree where each leaf node represents a character, and the value of each node is the number of times that character appears in the data. The tree is constructed so that the character with the lowest frequency is placed at the bottom of the tree, and the characters with higher frequencies are placed higher in the tree.
- Once the tree is constructed, assign a binary code to each character. The binary code is determined by starting at the tree's root and following the path to each character's leaf node.
The code for each character is the binary representation of the path from the root to that character's leaf node. The shorter the code for a character, the more frequently that character appears in the data.
Applications of Huffman Coding
Huffman coding is widely used in various applications, including data compression, image and video compression, audio compression, and lossless data transmission. The technique is also used in telecommunications and storing digital images and videos. Huffman coding is also used to implement certain algorithms, such as the JPEG image compression algorithm.
Advantages of Huffman Coding over Other Compression Techniques
One of the main advantages of Huffman coding over other compression techniques is its simplicity. Unlike other techniques, such as arithmetic or run-length encoding, Huffman coding can be implemented using only a few lines of code. This makes it an ideal solution for applications with limited computational resources, such as embedded systems or mobile devices.
One of the main advantages of Huffman coding over other compression techniques is its ability to provide a high compression ratio for data containing many repetitive characters. For example, text files that contain a large number of common words can be compressed to a very small size using Huffman coding.
Another advantage of Huffman coding is its ability to adapt to compressed data changes. If the frequency distribution of the characters in the data changes, the Huffman coding algorithm can easily adjust to reflect these changes without recompressing the entire data set. This makes Huffman coding an ideal solution for real-time data compression and transmission.
Efficiency and Space Complexity of Huffman Coding
Huffman coding is a very efficient compression technique.
The time complexity of the Huffman coding algorithm is O(n log n), where n is the number of characters in the data.
The space complexity of the algorithm is O(n), which requires only a moderate amount of memory to implement.
Implementation of Huffman Coding
Huffman coding can be implemented in various programming languages, including C, C++, Java, and Python. The basic steps involved in implementing Huffman coding are:
- Count the frequency of each character in the data.
- Create a binary tree where each leaf node represents a character, and the value of each node is the frequency of that character in the data.
- Assign a binary code to each character based on the path from the tree's root to each character's leaf node.
- Write the compressed data to a file or stream using the binary codes assigned to each character.
Practice Problems Based on Huffman Coding
Suppose there is a file that includes different characteristics along with their corresponding frequencies. If we apply Huffman coding to compress the data in this file, what can be determined?
1. Huffman code for each character
2. Average code length
3. Length of Huffman encoded message
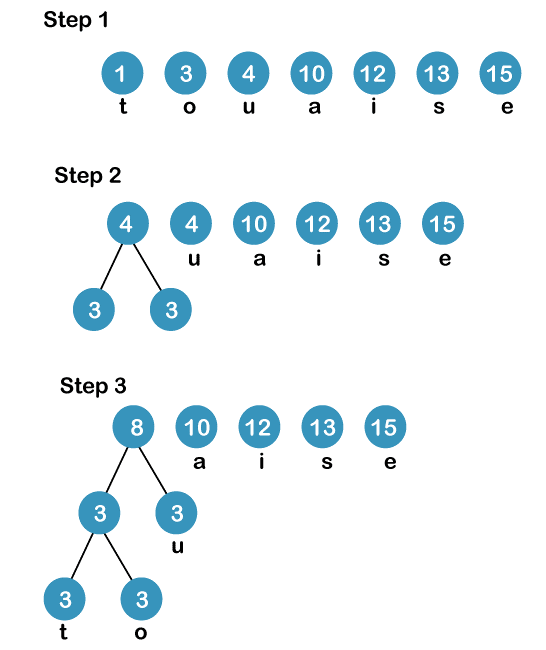
| CHARACTERS | FREQUENCIES |
| E | 15 |
| I | 12 |
| 0 | 3 |
| U | 4 |
| S | 13 |
| T | 1 |
| A | 10 |
SOLUTION –
The process of constructing a Huffman Tree involves the following steps:-
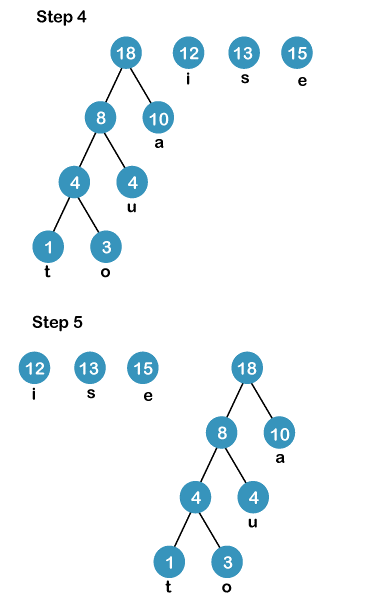
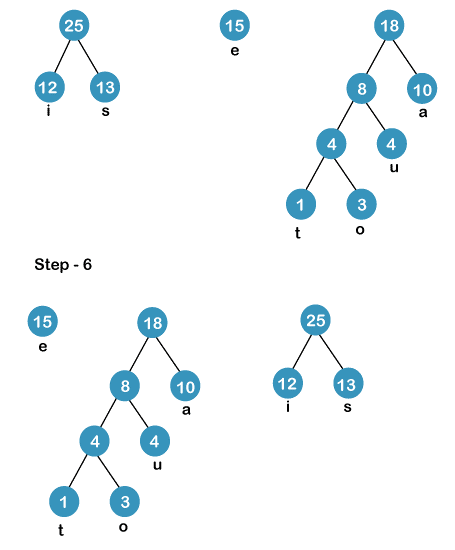
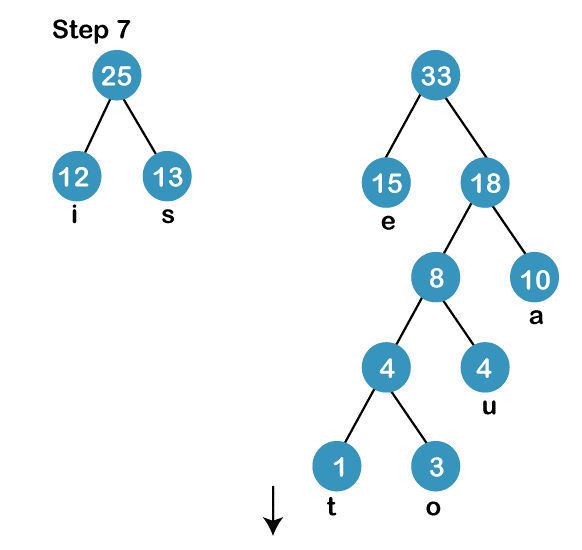
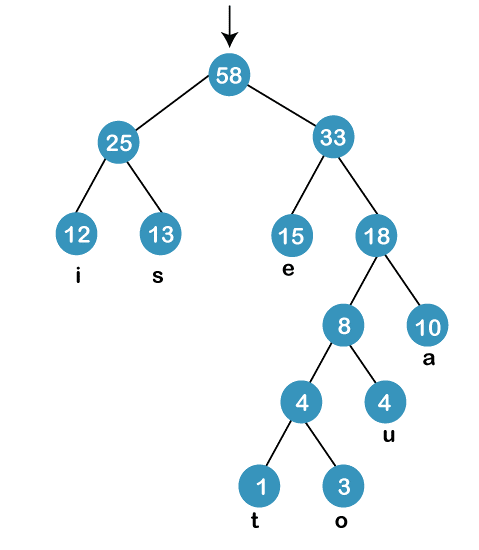
Next,
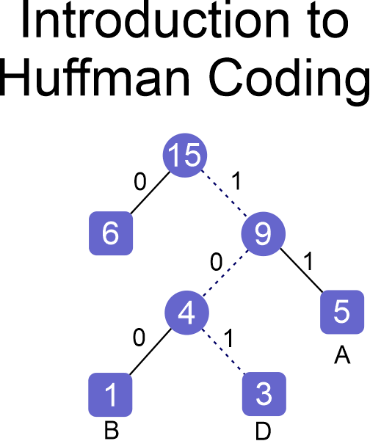
we need to assign weights to the edges of the Huffman Tree that has been constructed. The convention is to assign the weight '0' to the edges on the left side of the tree and the weight '1' to the edges on the right side of the tree.
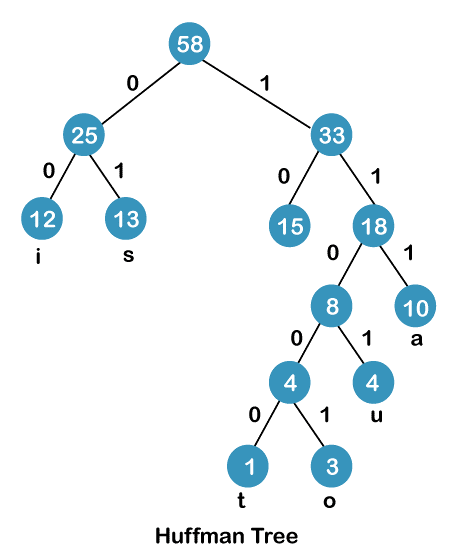
The modified Huffman tree refers to the Huffman tree structure that has been updated with weight assignment on its edges.
Conclusion
Huffman coding is a powerful and efficient data compression technique widely used in various applications. The technique is based on representing the characters in a file or data stream with a variable-length code. The characters that appear more frequently are represented with shorter codes, and the characters that appear less frequently are represented with longer codes. Huffman coding is a lossless compression technique, meaning no information is lost during the compression and decompression process. The benefits of Huffman coding, combined with its efficiency and versatility, make it an ideal solution for a wide range of data compression and transmission applications.