Data Structures Tutorial
The data structure is a way of storing and organizing data in a computer system. So that we can use the data quickly, which means the information is stored and held in such a way that it can be easily accessed later at any time. Data structures are used widely in almost every aspect of computer science, such as Operating systems, Compiler design, Artificial intelligence, Computer Graphics etc.
There are two types of data structure:
1. Primitive data structure
2. Non-primitive data structure
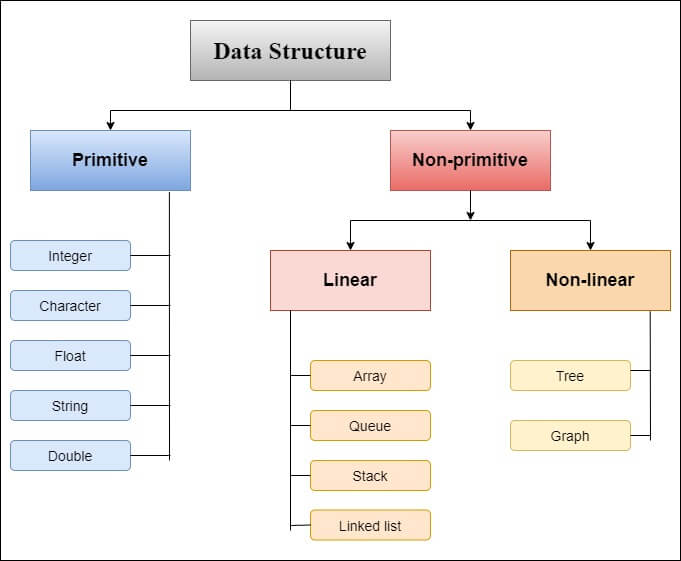
Primitive data structure
The primitive data structure can be directly controlled by computer commands. That means it is defined by the system and compiler.
There are the following types of Primitive data structure, that is shown in the figure:
1. Integer
2. Character
3. Double
4. Float
5. String
Integer: In the integer, it includes all mathematical values, but it is not include decimal value. It is represented by the int keyword in the program.
Character: The character is used to define a single alphabet in the programming language. It is represented by the char keyword in the program.
String: The group of the character is called a string. It is represented by the string keyword in the program. The string is written with a double quotation mark ("-"). For example: "My name is Bob".
Float and Double: Float and double is used for real value.
Non-primitive data structure
The Non-primitive data structure cannot be directly controlled by computer commands. The Non-primitive data structure is derived from the primitive data structure.
There are two types of non-primitive data structure:
1. Linear data structure
2. Non-linear data structure
Linear data structure
Linear data structures are those data structures in which data elements are stored and organized in a linear manner, in which one data element is connected to another as a line. For example, array, linked list, queue, stack.
Non-linear data structure
Non-linear data structures are those data structures in which data elements are not organized in a linear manner. In this, a data element can be associated with any other data element. For example, tree and graph.
Data Structure Operations
Various data structure operations are used to process the data in a data structure which is as follows:
- Traversing: Visiting each element of the data structure only once is called traversing.
- Searching: Finding the location of the record or data in the data structure is called searching.
- Inserting: Adding the same type of element to the data structure is called insertion. An element can be added anywhere in the data structure.
- Deleting: Removing an element from a data structure is called Deletion. An element can also be removed from anywhere in a data structure.
- Sorting: Arranging a record in a logical order in the data structure is called shorting.
- Merging: In the data structure, the record is stored in many different files. Adding these different files to a single file is called merging.
Algorithm
An algorithm is a finite number of steps of well-defined instructions for solving a specific problem. The algorithm is used to read any problem and define its solution. Time complexity and space complexity is checked by the algorithm.
Time complexity
The time complexity of an algorithm is the amount of time the algorithm takes to complete its process. Time complexity is calculated by calculating the number of steps performed by the algorithm to complete the execution.
Space complexity
The space complexity of an algorithm is the amount of memory used by the algorithm. Space complexity includes two spaces: Auxiliary space and Input space. The auxiliary space is the temporary space or extra space used during execution by the algorithm. The space complexity of an algorithm is expressed by Big O (O(n)) notation. Many algorithms have inputs that vary in memory size. In this case, the space complexity that is there depends on the size of the input.
Data Structure Index
- Data Structures Tutorial
- Asymptotic Notation
- Structure and Union
- Array
- Linked list
- Type of Linked list
- Advantages and Disadvantages of linked list
- Queue
- Implementation of Queue
- Stack
- Implementation of Stack
- Sorting
- Insertion sort
- Quick sort
- Selection sort
- Heap sort
- Merge sort
- Bucket sort
- Count sort
- Radix sort
- Shell sort
- Tree
- Traversal of the binary tree
- Binary search tree
- Graph
- Spanning tree
- Linear Search
- Binary Search
- Hashing
- Collision Resolution Techniques
Misc
- Priority Queue in Data Structure
- Deque in Data Structure
- Difference Between Linear And Non Linear Data Structures
- Queue Operations In Data Structure
- About Data Structures
- Data Structures Algorithms
- Types of Data Structures
- Big O Notations
- Introduction to Arrays
- Introduction to 1D-Arrays
- Operations on 1D-Arrays
- Introduction to 2D-Arrays
- Operations on 2D-Arrays
- Strings in Data Structures
- String Operations
- Application of 2D array
- Bubble Sort in Data Structures
- Insertion Sort in Data Structures
- Sorting Algorithms in Data Structures
- What is DFS Algorithm
- What Is Graph Data Structure
- What is the difference between Tree and Graph
- What is the difference between DFS and BFS
- Bucket Sort
- Dijkstra’s vs Bellman-Ford Algorithm
- Linear Queue Data Structure in C
- Stack Using Array
- Stack Using Linked List
- Recursion in Fibonacci
- Stack vs Array
- What is Skewed Binary Tree
- Primitive Data Structure in C
- Dynamic memory allocation of structure in C
- Application of Stack in Data Structures
- Binary Tree in Data Structures
- Heap Data Structure
- Recursion - Factorial and Fibonacci
- What is B tree
- what is B+ tree
- Huffman tree in Data Structures
- Insertion Sort vs Bubble Sort
- Adding one to the number represented an array of digits
- Bitwise Operators and their Important Tricks
- Blowfish algorithm
- Bubble Sort vs Selection Sort
- Hashing and its Applications
- Heap Sort vs Merge Sort
- Insertion Sort vs Selection Sort
- Merge Conflicts and ways to handle them
- Difference between Stack and Queue
- AVL tree in data structure c++
- Bubble sort algorithm using Javascript
- Buffer overflow attack with examples
- Find out the area between two concentric circles
- Lowest common ancestor in a binary search tree
- Number of visible boxes putting one inside another
- Program to calculate the area of the circumcircle of an equilateral triangle
- Red-black Tree in Data Structures
- Strictly binary tree in Data Structures
- 2-3 Trees and Basic Operations on them
- Asynchronous advantage actor-critic (A3C) Algorithm
- Bubble Sort vs Heap Sort
- Digital Search Tree in Data Structures
- Minimum Spanning Tree
- Permutation Sort or Bogo Sort
- Quick Sort vs Merge Sort
- Boruvkas algorithm
- Bubble Sort vs Quick Sort
- Common Operations on various Data Structures
- Detect and Remove Loop in a Linked List
- How to Start Learning DSA
- Print kth least significant bit number
- Why is Binary Heap Preferred over BST for Priority Queue
- Bin Packing Problem
- Binary Tree Inorder Traversal
- Burning binary tree
- Equal Sum
- What is a Threaded Binary Tree?
- What is a full Binary Tree?
- Bubble Sort vs Merge Sort
- B+ Tree Program in Q language
- Deletion Operation from A B Tree
- Deletion Operation of the binary search tree in C++ language
- Does Overloading Work with Inheritance
- Balanced Binary Tree
- Binary tree deletion
- Binary tree insertion
- Cocktail Sort
- Comb Sort
- FIFO approach
- Operations of B Tree in C++ Language
- Recaman’s Sequence
- Tim Sort
- Understanding Data Processing
- Convert binary tree to a doubly linked list
- Fundamental of Algorithms
- Introduction and Implementation of Bloom Filter
- Optimal binary search tree using dynamic programming
- Right side view of binary tree
- Symmetric binary tree
- Trim a binary search tree
- What is a Sparse Matrix in Data Structure
- What is a Tree in Terms of a Graph
- What is the Use of Segment Trees in Data Structure
- What Should We Learn First Trees or Graphs in Data Structures
- All About Minimum Cost Spanning Trees in Data Structure
- Convert Binary Tree into a Threaded Binary Tree
- Difference between Structured and Object-Oriented Analysis
- FLEX (Fast Lexical Analyzer Generator)
- Object-Oriented Analysis and Design
- Sum of Nodes in a Binary Tree
- What are the types of Trees in Data Structure
- What is a 2-3 Tree in Data Structure
- What is a Spanning Tree in Data Structure
- What is an AVL Tree in Data Structure
- Given a Binary Tree, Check if it's balanced
- B Tree in Data Structure
- Convert Sorted List to Binary Search Tree
- Flattening a Linked List
- Given a Perfect Binary Tree, Reverse Alternate Levels
- Left View of Binary Tree
- What are Forest Trees in Data Structure
- Compare Balanced Binary Tree and Complete Binary Tree
- Diameter of a Binary Tree
- Given a Binary Tree Check the Zig Zag Traversal
- Given a Binary Tree Print the Shortest Path
- Given a Binary Tree Return All Root To Leaf Paths
- Given a Binary Tree Swap Nodes at K Height
- Given a Binary Tree Find Its Minimum Depth
- Given a Binary Tree Print the Pre Order Traversal in Recursive
- Given a Generate all Structurally Unique Binary Search Trees
- Perfect Binary Tree
- Threaded Binary Trees
- Function to Create a Copy of Binary Search Tree
- Function to Delete a Leaf Node from a Binary Tree
- Function to Insert a Node in a Binary Search Tree
- Given Two Binary Trees, Check if it is Symmetric
- A Full Binary Tree with n Nodes
- Applications of Different Linked Lists in Data Structure
- B+ Tree in Data Structure
- Construction of B tree in Data Structure
- Difference between B-tree and Binary Tree
- Finding Rank in a Binary Search Tree
- Finding the Maximum Element in a Binary Tree
- Finding the Minimum and Maximum Value of a Binary Tree
- Finding the Sum of All Paths in a Binary Tree
- Time Complexity of Selection Sort in Data Structure
- How to get Better in Data Structures and Algorithms
- Separate Chaining vs Open Addressing
- Time and Space Complexity of Linear Data Structures
- Abstract Data Types in Data Structures
- Binary Tree to Single Linked List
- Count the Number of Nodes in the Binary Tree
- Count Total No. of Ancestors in a Binary Search Tree
- Elements of Dynamic Programming in Data Structures
- Find cost of tree with prims algorithm in data structures
- Find Preorder Successor in a Threaded Binary Tree
- Find Prime Nodes Sum Count in Non-Binary Tree
- Find the Right Sibling of a Binary Tree with Parent Pointers
- Find the Width of the Binary Search Tree
- Forest trees in Data Structures
- Free Tree in Data Structures
- Frequently asked questions in Tree Data Structures
- Infix, Postfix and Prefix Conversion
- Time Complexity of Fibonacci Series
- What is Weighted Graph in Data Structure