Python Pickle
The pickle is a module that enables serialization and de-serialization of the structure of the object in python. Pickling is the process that uses the protocols to convert the Python object hierarchy into the byte stream. The process of converting byte stream into Python object hierarchy is termed unpickling. Pickling is also called serialization, while the inverse operation that is unpickling is called de-serialization.
Python Pickle Dump and Python Pickle Load
pickle.dump() and pickle.load() are two functions in the pickle module that are used to store and retrieve data using this module. In order to use both these functions, it is necessary to import the pickle module into your program.
Once you have imported the pickle module into your program, then the next step will be to add the object data to the file. To do so, you will have to use the pickle.dump() function. This function takes three arguments, where the first argument contains the object that is to be stored in the file, and the second argument gives the file object that is obtained when the desired file is opened in the write-binary mode. While the third argument determines the protocols, this argument is of key-value type.
The two protocols that are available to be used in the third argument are:
- Pickle.HIGHEST_PROTOCOL
- Pickle.DEFAULT_PROTOCOL
Now let’s implement the program to store the data in a file using pickle.
import pickle
# data items you want to enter in the file
total_data = int(input('Enter the number of dataitems: '))
dataitems = []
# Take the value of the data items from the user
for i in range(total_data):
raw = input('Enter the data '+str(i)+' : ')
dataitems.append(raw)
# enter the file you want to insert data in
# Open the file in write-binary mode
file = open('file_1', 'wb')
# enter the data entered to that file
pickle.dump(dataitems, file)
# close the file after performing the operation
file.close()
You can enter the data values in the file using this program and once it is executed it will create a file and store those data values in the file.
Output:
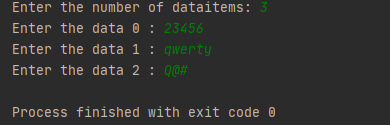
Python Pickle Load
Now, you have successfully entered the data, you should be able to retrieve that data too in order to use it. This function enables to retrieve of the data from the file. The data values can easily be retrieved when you open the file in read-binary mode using this function. The primary parameter passed to this function is the file object from which information is to be retrieved.
Now let’s write a code to retrieve the information that was stored in the above example by using pickle load.
import pickle
# Enter the file in which data was stored earlier
#Open the file in read binary mode
file = open('file_1', 'rb')
#Now load the information from the file using pickle.load() function
dataitems = pickle.load(file)
# close the file once the information is retrieved
file.close()
print('The data stored in the file is as follows:')
count = 0
for item in dataitems:
print('The data stored ', count, ' is : ', item)
count += 1
Output:
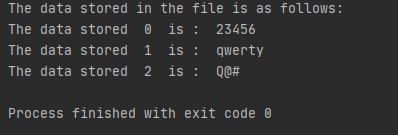
Thus, by using the above two functions you have successfully stored and retrieved information from a file.
Note: The pickle module is not safe when dealing with untrusted data. So, use pickle only with the trusted data otherwise use more secured formats like JSON.
Data that can be Pickled
Not every type of data written in python can be pickled. However, Python-pickle enables to pickle only the given format of data:
- None and True, False
- All the types of numbers including floating, complex and integers
- strings, bytes, byte arrays
- tuples, lists, sets, and dictionaries but they must contain the objects that are prickleable by themselves
- functions defined at the top level of a module but they should be defined by def and not lambda
- built-in functions defined at the top level of a module
- classes that are defined at the top level of a module
- instances of such classes whose __dict__ or the result of calling __getstate__() is prickleable
When you try to pickle any object that cannot be pickled, it will throw a PicklingError exception; it may be possible that some of the bytes are written to the file before raising the exception. And when you attempt to pickle the recursive data structure, it may cause a RecursionError as there is a limit to the recursion depth that can be reached. You can keep a check on this limit with sys.setrecursionlimit().
Note: When you try to pickle any function both built-in or user-defined this only pickles the name of the function and the module name in which the mentioned function is present. It does not pickle the code inside the function nor the attributes of the function.
Additional Information
- The use of prickle protocol is limited to python and is not necessary that it support other languages. Therefore, it is not possible to transfer and access the data in any other language. This is a major restriction with pickle.
- Python uses the latest version of the pickle available by default. It can be manually changed by the user.
- Pickle may execute differently with different versions of Python itself.
Data stream format
We know that prickle protocols are only limited to the Python programming language. This act both as an advantage and a disadvantage. As an advantage, there is no restriction imposed by any other external protocols like in the case of JSON but at the same time, it is a disadvantage as we cannot use any other programming language when dealing with pickled data.
Pickletools is a module that has the tools, especially to study the data streams that are produced by the pickle module. This has the opcodes regarding the protocols of the pickle. Till now there have been six protocols that are used by the pickle module to implement pickling. The latest versions of the Python are compactible to the higher protocol.
- Protocol version 0 is the earliest protocol that was available to pickle the data. It was a “human-readable” protocol that was compatible with the older version of Python.
- Protocol version 1 was the binary format protocol that was also limited
- Protocol version 2 provides much more efficient pickling of new-style classes.
- Protocol version 3 was added in Python 3.0 was introduced as the external support for the byte objects that were not unpickled by Python 2x and was added as the default protocol.
- Protocol version 4 was introduced in Python 3.4. It was an extension of the earlier protocols as it allowed the user to pickle or unpickle larger data and allow the user to convert more types of objects. It is the default protocol starting with Python 3.8.
- Protocol version 5 is the latest protocol that was introduced with Python 3.8. It supports the out-of-band data and speed up the in-band data.
Note: Pickle only reads and writes the objects of the file, it does not resolve the problem with the concurrent access to its file objects and neither does it resolves the issue of naming such objects. This module is used to transform the objects into the byte stream. The structure of the byte stream is just the same as that of the complex object. These byte codes can be written on a file or they can also be sent across the network or can be stored in databases by using the shelve module that provides an interface to the user to pickle and unprickle objects on DBM-style database files.