Drop() Function in Python
Drop() Function:
The python programming language consists of various libraries; some of them are pandas and matplotlib. Data scientists mainly use the pandas library to analyze the data more easily and faster. The pandas provide a series or a dataframe to organize the data in a labelled format. The pandas library in python is faster and simple than any other library. The pandas are built over the Numpy for operating the python libraries; we require the Numpy.
The dataframe which is created in the pandas is mutable. That is, we can change the data present in the dataframe, we can insert the data, or can delete the data present in the dataframe. The pandas contain many built-in functions to perform various operations. One of them is the drop( ) function, used to drop or remove any column or rows present in the dataframe using the index of the columns or rows.
Syntax:
dataframe.drop(labels, axis, index, columns, level, in place., errors)
Parameters:
- Labels: It provides the information about the labels or indexes to drop. We can take the input as a list if we want to drop more than one column or row.
- Axis: It will provide the information about which axis we need to check. By default, it will be set as zero. If we want to drop a row, we need to provide it as column to remove the specified column. If we want to remove the row, we need to provide the axis as the index; it will drop the specified row. It is an optional parameter.
- Index: It will provide the name of the rows to drop. It is also an optional parameter it can be used instead of the labels parameter.
- Columns: It will provide the name of the columns to drop. It is also an optional parameter it can be used instead of the labels parameter.
- Level: The dataframe may consist of the hierarchical tables so that it may consist of the multi-index; this parameter will provide the information about at which level we need to check in a multi-index dataframe. It is also an optional parameter; by default, it will be set as None.
- In place: This parameter has only two values, True or False; by default, it will be set as False. If it is set as True, the removal operation is performed in the given dataframe. If it is False, it will return a copy of the column where the operation is performed.
- Errors: It has only two values, ' raise’ and ‘ignore '. It is also an optional parameter; it will provide information on whether we need to consider the errors or not.
- Return type: This function will return the dataframe with the removed values.
Examples:
- Dropping the rows:
In this example, we will observe how we can drop the rows from the dataframe with the help of the index provided.
Code:
# importing pandas module
import pandas as pd
#Obtaining the data from the CSV file and creating the dataframe
data = pd.read_csv("nba.csv", index ="Name" )
# removing the values
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter"], in place = True)
# print the dataframe after performing an operation
dataOutput:
We can observe in the output that the updated dataframe doesn't contain the passed values; it only consists of the reaming data because the inplace is taken as True.
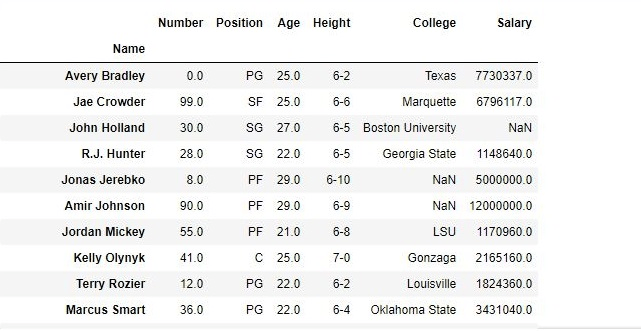
Before using the drop( ) function:
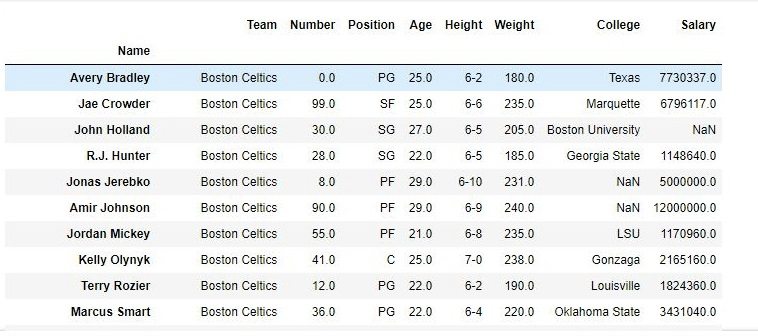
After using the drop( ) function:
2. Dropping the columns:
The columns are dropped from the dataframe by fixing the column as the label; the values are dropped from the dataframe with the help of the index values provided.
Code:
# importing pandas module
import pandas as pd
#Obtaining the data from the CSV file and creating the dataframe
data = pd.read_csv("nba.csv", col ="Name" )
# dropping passed columns from the dataframe
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# print the dataframe
dataOutput:
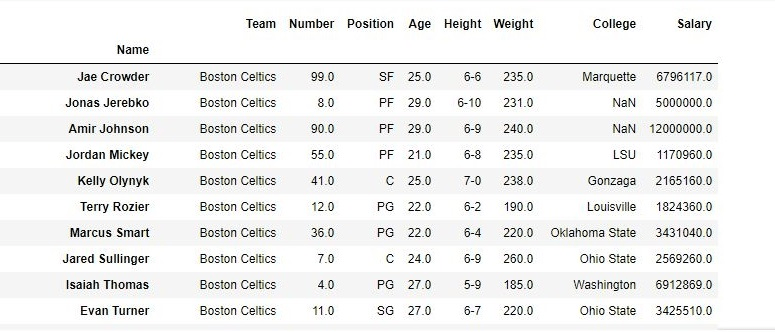
Here the axis is set as one, so it will drop the columns from the dataframe. Here, we can observe that the final output doesn’t contain the passed values, and the changes are made in the original dataframe because the inplace is True.
Before usingdrop( ) function:
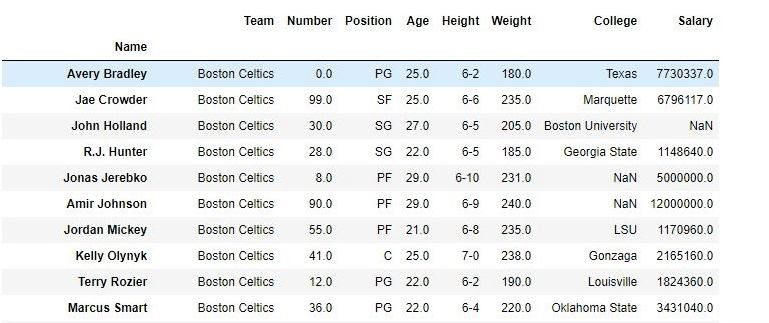
After using drop( ) function: