Standard Scalar in Python
Python is a vast and open-source language that contains many libraries, modules, and functions. These functions in python are reusable codes where we don’t need to type the whole code when we needed; instead, we can name the code and call the name every time you require, and this piece of code will be considered a function. In this article, we will know about a critical function in python: StandardScaler () function taken from the sklearn library.
sklearn or Scikit-learn is a python library used for machine learning. It contains many features like classification, regression, clustering, and Dimensionality reduction algorithms. To build machine learning models, we use Sklearn, so it cannot be used for manipulating Data and summarizing data.
It also provides efficient machine learning and statistical modeling tools, including python regression, classification, and clustering. This library is built upon NumPy, SciPy, and Matplotlib in python. With this library, it is easy to write machine learning algorithms. StandardScaler() function also does all these operations In datasets.
This function is used to standardize the given data in python. So let us look into the need for this function.
What is standardization?
To understand the concept of standardization, we first need to know the idea of scaling. Scaling is the basic thing that we do while modeling an algorithm having data sets. For creating the data for algorithms, we generally use the inputs taken from surveys, quizzes, research, scraping, etc. And this collected data will have dimension values that are scaled together. Many scales together create a data set.
Having a random data set will always give a biased output, leading to a mistake in the accuracy rates. So, it is important to scale the data before sending it to the algorithm.
Now we use standardization, which is a scaling technique that makes the data set free by converting the whole data in a statistical form into 0s and 1s. Where
- 0 refers to mean
- One refers to the standard deviation
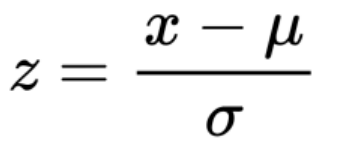
For standardization, we use the equation given below:
This equation scales the complete data into 0, which is the mean and unit variance. In this way, we standardize the data set. Now let us see how and where we use this function in python coding and dealing with data sets.
StandardScaler() Function:
As we know, every function is extracted from a library. In the same way, the sklearn library offers this StandardScaler() to standardize the values in a data set into the normal form.
Let us look at the syntax for this function:
object = StandardScaler()
object.fit_transform(data)
Therefore, in these commands, we first created an object with the standard scalar() function. And next, we used the fit_transform() along with the data set to be standardized. We also have to ensure that the data set follows normal distribution to be applicable for standardization.
Let us look at an example code to check the concept of standarsclar().
Example
From sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
dataset = load_iris()
object= StandardScaler()
# Splitting an independent and a dependent variables
i_data = dataset.data
response = dataset.target
# standardization
scale = object.fit_transform(i_data)
print(scale)
Output:

In the above code, we first imported the required libraries and then imported functions from the sklearn library. Then, we also imported StandardScaler() function.
Iris is a very commonly used data set in any python test code in data modification. So, we imported the iris dataset from sklearn—datasets library. Then we put an object name as StandardScaler() function. Then we split the independent and the dependent values using those commands in the code above. We finally do the standardization and apply that function to the data set.
This is how we get a standardizes data for modeling algorithms. Therefore, with this standardized data we get a proper output and there will be no need to check the accuracy like before code.
Methods of the standard scaler class:
There are different methods of the standard scaler class which are as follows:
- fit(X,[,y, sample_weight]): With this method, we can calculate the mean and the standard deviation which we use later for measuring data.
- Fit_transform(X[,y]): By using this method, we fix the parameters of the data and them transform it.
- Get_feature_names_out([input_features]): Using this method, we can get the new names for the transformation.
- Get_params([deep]): We will get the parameters of the unique estimator by using this method.
- Inverse_transform(X[, copy]): Using this function, we can decrease the size of the data so that it can match its original form.
- Partial_fit(X[, y, sample_weight]): By using this method, we can compute the mean and standard deviation online for measuring later.
- Set_params(**params): This method is used to set the values of estimation parameters.
- Transform(X[, copy]): With the help of this method, we can transform the data by using parameters which are pre-installed in the class.
Conclusion
As far asb, this article has covered what StandardScaler() function is, the use of this function, the way to use it in the code, and finally, the way we imported this function from the library. Also, to understand this concept properly, we have used a code in which we have worked in an already created dataset.