Python Word Tokenizer
Python Overview
Python is an Object-Oriented high-level language. Python is designed to be highly beginner-friendly. Python has an English-like syntax, which is very easy to read. Python is an interpreted language which means that it uses an interpreter instead of the compiler to run the code. The interpreted language is processed at the run time thus takes less time to run.Python is also interactive, so we can directly run programs in the terminal itself.
Installing Python
To download Python go to the link https://www.python.org/downloads/and click on the download option. If you already have Python, you can check the version by using this command:
Python --version
After installing, to verify the installation, use this command:
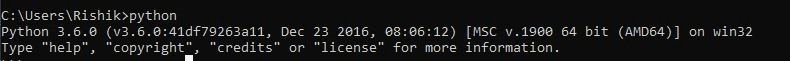
If this commands runs without an error, it means we have successfully installed Python.
Tokenize
Tokenization is the process of dividing the text into smaller parts. These tokens are used to find patterns, predict the next tokens, and for stemming and lemmatization. The machine learning models like chatbots, Sentimental analysis, and other text models use the NLP. Dealing with text is a slightly different task than normal numeric data. Tokenization is one of the parts of the processing of text data to train for the model.
Tokenization is to divide a sentence into different tokens, which can be found in other sentences. Every sentence is made up of tokens.
Let us understand tokenization with an example:
Example: “TutorialandExample provides tutorials for all technology”
After performing the termination to this sentence, we will get the following as a result:
[‘ TutorialandExample’, ‘provides’, ‘tutorials’, ‘for’, ‘all’, ‘technology’]
As you can see, we have all the words in the sentence as the output. When a word is repeated in the original sentence, we still get only a token for that word.
There are many ways to do tokenization. First of all, we can directly use the split() function in Python.
Tokenization using split()
The split () method is used to split the words in a string. By default, the words are separated based on space, but we can also define the separator by ourselves.
Example:
Let us use the split() function to split the strings in tokens.
String = “ Lorem ipsum dolor sit amet, consectetur adipiscing elit”
Print(String.split())
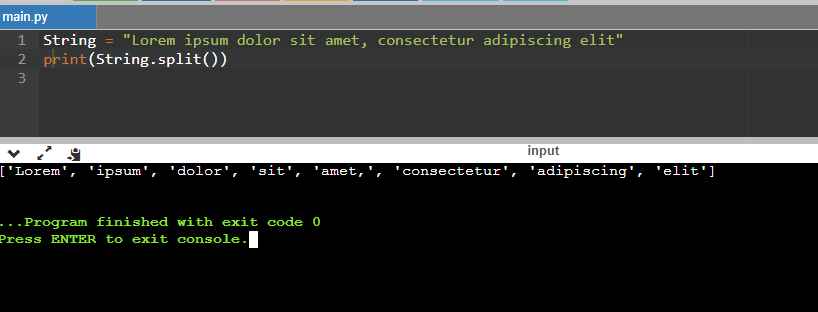
We have successfully created the tokens by using the split() function. The one issue we will find with the split() function is that it will give all the words as output. If a single word is repeating two times, it will return the word two times too.
Tokenization using word_tokenize()
The better and more efficient way of tokenizing the sentence is to use the word_tokenize() function. It is provided by a library called Natural Language Toolkit, also knows as NLTK. NLTK provides a module named NLTK tokenize, which contains various functions to tokenize. The function word_tokenize() is used to tokenize the sentences. The output is a list and also contains the punctuations marks. The output can also be converted into a dataframe for better understanding. We can also perform operations on it such as stemming, punctuation removal, etc.
To use the tokenizer, we need to install the NLTK library. To install NLTK, run the command below in your terminal:
$ pip install --user -U nltk
We can verify the installation by importing the library.
Import nltk
If the above command does not show any error, then we have successfully installed the library.
Example for word tokenization:

Explanation:
In the first line, we have imported the function from the nltk. Tokenize module. After which, we have defined the string and called the function. In the result, you can see the tokens returned in a list.
Tokenizing Sentences
We can also tokenize the sentence using the NLTK library. Sentence tokenization is useful in many cases, like finding out the average word counts in a sentence, etc. For the tokenization of sentences, we have the function sent_tokenize().
Example:

> from nltk.tokenize import sent_tokenize
>>> sentences = "TutorialandExample is a Noida based IT Company. we deals in Training | Development | SEO. TutorialandExample provides easy and point to point learning of various online tutorials such as Java Tutorial, Core Java Tutorial, Android, Design Pattern, JavaScript, AJAX, SQL, Cloud Computing, Python etc."
>>> print(sent_tokenize(sentences))
['TutorialandExample is a Noida based IT Company.', 'we deals in Training | Development | SEO.', 'TutorialandExample provides easy and point to point learning of various online tutorials such as Java Tutorial, Core Java Tutorial, Android, Design Pattern, JavaScript, AJAX, SQL, Cloud Computing, Python etc.']
Explanation:
As we can see, the method sent_tokenize has tokenized all the sentences from our paragraph. The sentences are stored in a list.