.iloc function in Python
The .iloc function in Python is a powerful tool for accessing and manipulating data within a Pandas DataFrame. This function is one of several data selection methods available in Pandas and is particularly useful when working with large datasets. The .iloc function allows you to select data based on its integer-based index location, rather than its label. This makes it a useful tool for slicing and dicing data to get exactly the subset of data you need.
Pandas is a popular library for data analysis and manipulation in Python. It provides data structures for efficiently storing large datasets and tools for working with them. The primary data structure in Pandas is the DataFrame, which is a two-dimensional table of data with rows and columns. The rows are identified by an index, and the columns are identified by a label. When working with data in a DataFrame, it is often necessary to extract a subset of the data for further analysis. This is where the .iloc function comes in.
The .iloc function works by selecting data based on the integer-based index location of the data within the DataFrame.
The syntax for using the .iloc function is as follows:
df.iloc[row_indexer, column_indexer]
Here, row_indexer and column_indexer are the integer-based indexing values used to select the rows and columns, respectively. They can take various forms, such as integer values, slices, lists, or boolean masks.
For example, the following code selects the first three rows and first two columns of a DataFrame using iloc:
Code -:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data)
selected_data = df.iloc[0:3, 0:2]
print(selected_data)Output -:
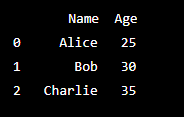
In this example, iloc[0:3, 0:2] selects the first three rows and first two columns of the DataFrame. The resulting DataFrame selected_data contains the selected data.
1) Selecting specific rows and all columns:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data)
# Selecting the second and fourth row and all columns
selected_data = df.iloc[[1, 3], :]
print(selected_data)
Output -:
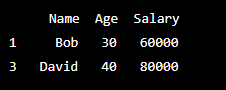
In this example, iloc[[1, 3], :] selects the second and fourth rows and all columns of the DataFrame.
2) Selecting specific columns and all rows:
Code-:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data)
# Selecting the first and third columns and all rows
selected_data = df.iloc[:, [0, 2]]
print(selected_data)Output-:
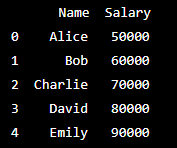
In this example, iloc[:, [0, 2]] selects the first and third columns and all rows of the DataFrame.
3) Using boolean indexing with iloc:
Code -:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data)
# Selecting rows where the Age is greater than 30 and all columns
selected_data = df.iloc[df['Age'] > 30, :]
print(selected_data)Output -:
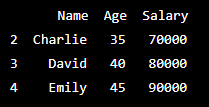
In this example, iloc[df['Age'] > 30, :] selects the rows where Age is greater than 30 and all columns of the DataFrame using boolean indexing.
4) Selecting specific rows and columns based on index values:
Code -:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# Selecting rows 'a', 'c' and columns 'Name' and 'Age'
selected_data = df.iloc[[0, 2], [0, 1]]
print(selected_data)
Output -:
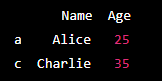
In this example, iloc[[0, 2], [0, 1]] selects the rows with index labels 'a' and 'c' and columns 'Name' and 'Age' of the DataFrame.
5) Selecting a single scalar value using iloc:
Code -:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# Selecting scalar value at row 'b' and column 'Salary'
selected_data = df.iloc[1, 2]
print(selected_data)Output -:
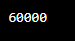
In this example, iloc[1, 2] selects the scalar value at the row with index label 'b' and column 'Salary' of the DataFrame.
6) Selecting a range of rows and columns using iloc:
Code -:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 60000, 70000, 80000, 90000]}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# Selecting rows 'a' to 'c' and columns 'Age' to 'Salary'
selected_data = df.iloc[0:3, 1:]
print(selected_data)Output -:
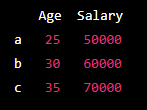
In this example, iloc[0:3, 1:] selects rows with index labels 'a' to 'c' and columns 'Age' to 'Salary' of the DataFrame.