How to Concat two Dataframes in Python
Using Pandas dataframe, we can concat two dataframes or series in Python. So let's take a brief introduction to what is Pandas in Python.
Pandas is a library typically used for data analysis and manipulation in Python programming. It is a dataframes in Python.
The pandas dataframe is a tabular data structure with labelled axes, rows, and columns that is two-dimensional, immutable, and heterogeneous. There are three main parts to a pandas dataframe: data, rows, and columns.
In Pandas, we have pandas.concat() command to concatenate dataframes. The dataframes can be concatenated together. The dimension on which you want to concatenate can be chosen.
Parameters of pandas.concat()
We write this command as:
Syntax:
pandas.concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
Concatenate pandas objects along one axis while allowing set logic to be applied along the other axes as an option.
Pandas data frame offers several methods for quickly combining series, dataframe, and Panel objects.
Let’s understand the parameters one by one:
- objs: A sequence or mapping of series, dataframe, or Panel objects make up this parameter.
Unless a mapping is given, the values will be chosen, and the sorted keys will be used as the keys argument. Unless they are all None, a ValueError would be generated, and any None objects will be silently deleted.
Let’s understand it by taking an example.
Example
# code goes from here
# import Pandas
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
# using concat command to concat dataframes
new_df = pd.concat([df1, df2])
print(new_df)
Output:
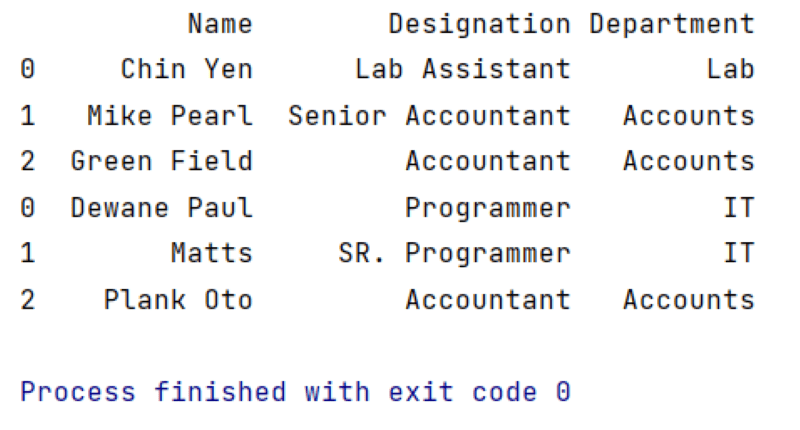
In the above example, we have 2 dataframes, df1 and df2. We can merge both tables using the pd.concat() method.
- axis: It is to concatenate along {0,1}; default 0.
Let’s understand it by taking an example.
Example
# code goes from here
# import Pandas
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Chin Yen', '1234567879', 'USA'],
['Mike Pearl', '2152313213', 'Scood'],
['Green Field', '4517825469', 'New Start']
], columns=["Name", "Phone no.", "Country"]
)
# using concat command to concat dataframes
new_df = pd.concat([df1, df2], axis=1)
print(new_df)
Output:
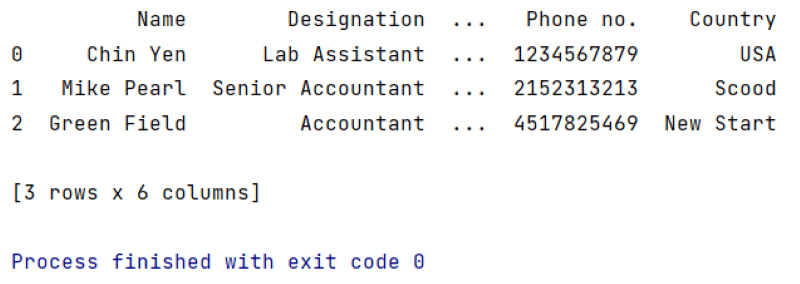
In the above example setting the axis value equal to 1, both data frames would be joined along with the index.
- Join: How to handle other axis' indexes (es).
{‘inner’, ‘outer’}, default ‘outer’.
Inner is for intersection, and outer is for a union.
Let’s understand it by taking an example.
Example
# code goes from here
# import Pandas
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Chin Yen', '1234567879', 'USA'],
['Mike Pearl', '2152313213', 'Scood'],
['Green Field', '4517825469', 'New Start']
], columns=["Name", "Phone no.", "Country"]
)
# using concat command to concat dataframes
new_df1 = pd.concat([df1, df2], join='outer')
new_df2 = pd.concat([df1, df2], join='inner')
print(f'''Outer join
{new_df1}
Inner join
{new_df2}
''')
Output:
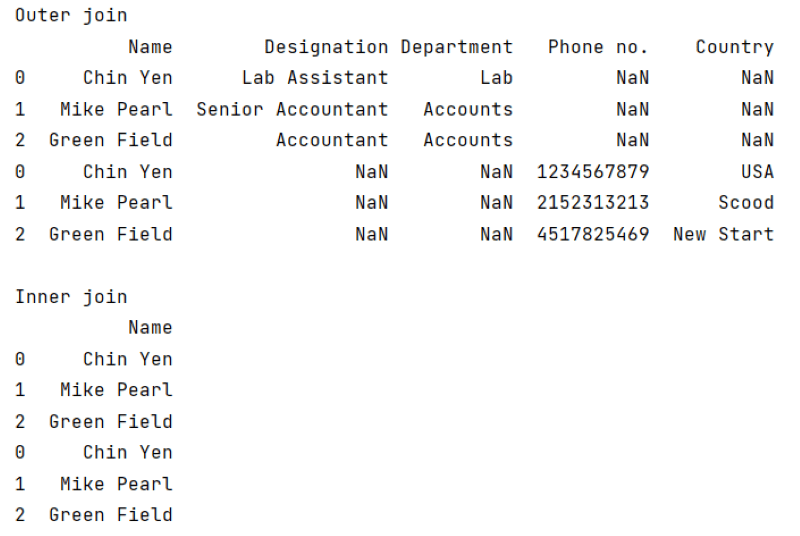
In the above example, when the value of the join parameter is equal to the outer, it returns a new DataFrame, having all columns. But when the value of the join parameter is equal to the inner, it returns a new DataFrame, which has columns common in both DataFrame.
- ignore_index: bool, default is ‘False’
The results' axis will be labelled 0,..., n - 1. This is helpful when concatenating objects with the concatenation axis lacks relevant indexing information. The join still respects the index values on the other axes.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
new_df1 = pd.concat([df1, df2])
new_df2 = pd.concat([df1, df2], ignore_index=True)
print(f'''with default value
{new_df1}
after setting ignore_index True
{new_df2}
Output:
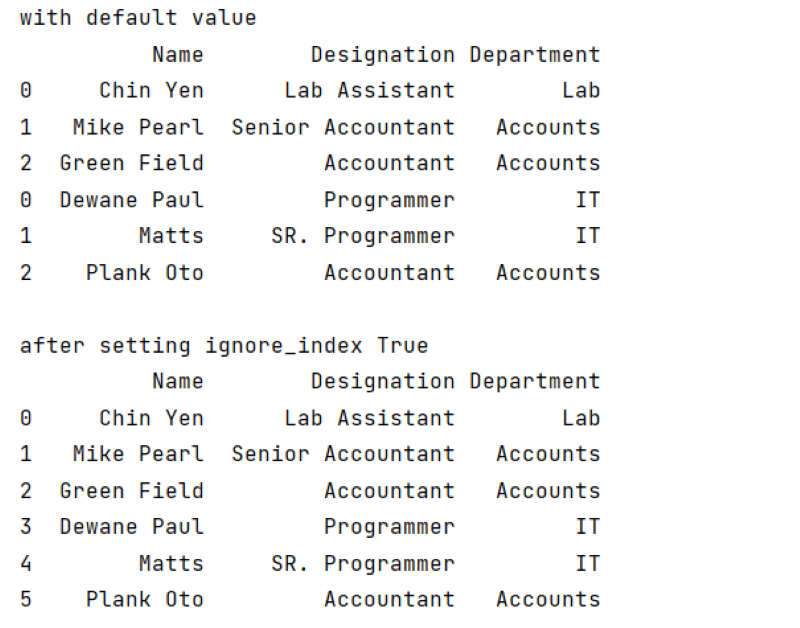
In the above example, when the value of ignore_index is equal to false, both DataFrames will be from indexes 0 to the number of elements each DataFrames have. But when the value of ignore_index is true, the number of indexes will be from 0 to the total number of elements.
- Keys: sequence, default is 'None'.
It should contain tuples if more than one level is passed. Create a hierarchical index with the passed keys at the top. This means adding an identifier in a specific order to the result indexes.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
new_df = pd.concat([df1, df2], keys=["level 1", "level 2"])
print(new_df)
Output:

In the above example, we created 2 levels using keys. It created multi indexed hierarchy.
- Levels: Utilizing certain levels (unique values) to build a MultiIndex If not, it will be assumed from the keys.
The default is ‘None’.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
data = pd.concat([df1, df2], keys=["level 1", "level 2"], levels=[["level 1", "level 2", "level 3"]])
print(data)
print("\nlevels in table")
print(data.index.levels)
Output:

In the above example, we have 2 levels used in the table, but there are 3 levels defined using the level parameter.
- Names: level names for the generated hierarchical index.
The default is ‘None’.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
data = pd.concat([df1, df2], keys=["level 1", "level 2"], names=["level", "index"])
print(data)
Output:
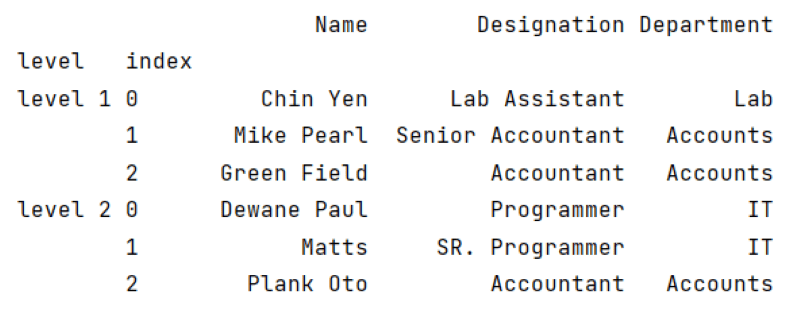
In the above example, we provided the name of levels and indexes using the name parameter.
- verify_integrity: bool,default is False.
Verify if there are any duplicates in the newly concatenated axis. Comparatively speaking to the actual data concatenation, this can be highly expensive.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
data = pd.concat([df1, df2], verify_integrity=True)
print(data)
Output:
ValueError: Indexes have overlapping values: Int64Index([0, 1, 2], dtype='int64')
In the above example, we are getting an error because the values of indexes are repeating. If we set ignore_index to True, we will not get any error.
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"]
)
data = pd.concat([df1, df2], verify_integrity=True, ignore_index=True)
print(data)
Output:

Here we can see there is no repetition of data. That’s why there is no error.
- Sort: bool, default is False.
If the join is "outer," sort the non-concatenation axis if it is not already aligned. This has no impact when join=” inner”, which already maintains the order of the non-concatenation axis.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"],
index=[1, 3, 2]
)
df2 = pd.DataFrame([
['Chin Yen', '1234567879', 'USA'],
['Mike Pearl', '2152313213', 'Scood'],
['Green Field', '4517825469', 'New Start']
], columns=["Name", "Phone no.", "Country"],
index=[1, 3, 2]
)
data_1 = pd.concat([df1, df2], axis=1)
data_2 = pd.concat([df1, df2], axis=1, sort=True)
print(f''' when sort=False
{data_1}
when sort=True
{data_2}
''')
Output:
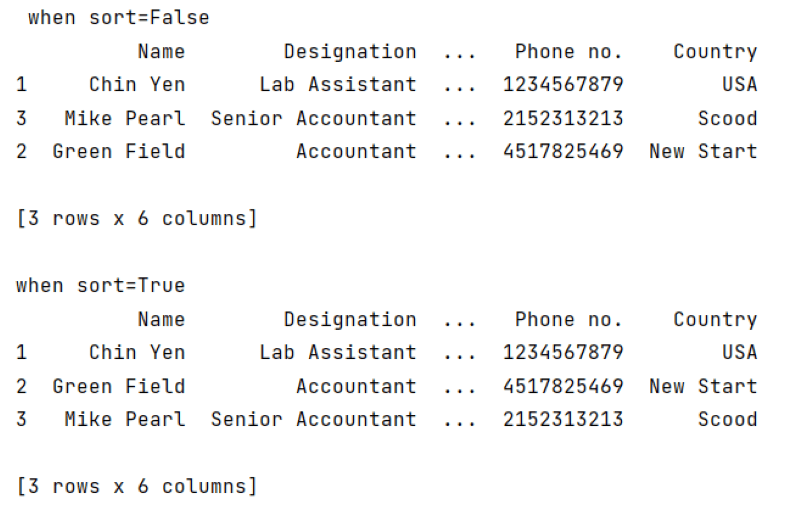
In the above example, we use the sort parameter. When the sort value is False, it only concatenates data frames together, but when we use the sort value is True, it will concatenate data frames after sorting.
- Copy: bool, Default is True.
If it is False, it does not copy data unnecessarily.
Let’s understand it by taking an example.
Example
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"],
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"],
)
data = pd.concat([df1, df2])
data[data.index == 1] = data[data.index == 1].replace("Accounts", "IT")
print(f'''content in data
{data}
content in df1
{df1}
content in df2
{df2}
''')
Output:
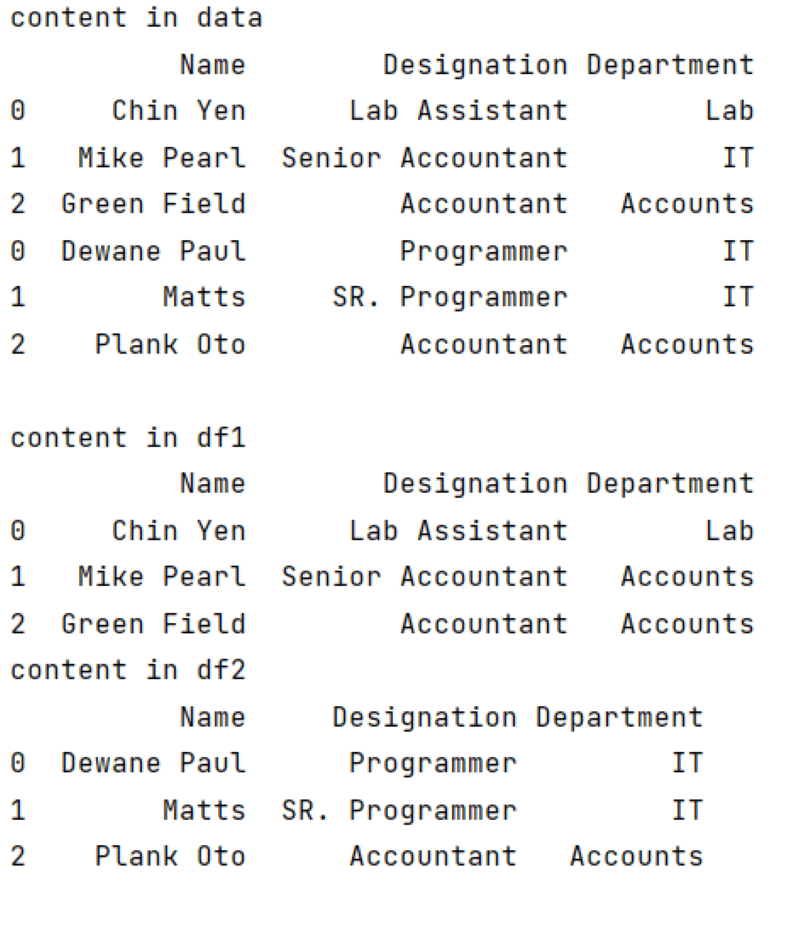
In the above example, we have DataFrame named data, made by contacting df1 and df2. When we make data DataFrame, there is no change in df1 or df2. Let’s try it when the value of the copy parameter is False.
import pandas as pd
df1 = pd.DataFrame([
['Chin Yen', 'Lab Assistant', 'Lab'],
['Mike Pearl', 'Senior Accountant', 'Accounts'],
['Green Field', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"],
)
df2 = pd.DataFrame([
['Dewane Paul', 'Programmer', 'IT'],
['Matts', 'SR. Programmer', 'IT'],
['Plank Oto', 'Accountant', 'Accounts']
], columns=["Name", "Designation", "Department"],
)
data = pd.concat([df1, df2], copy=False)
data[data.index == 1] = data[data.index == 1].replace("Accounts", "IT")
print(f'''content in data
{data}
content in df1
{df1}
content in df2
{df2}
''')
Output:

In the above example, we can see when we make any change in data, and It also changes the values of df1 or df2. As we change the value of the 2nd row (index = 1) from Accounts to IT, It is also changed in df1.