Python | Read csv using pandas.read_csv()
Python is an excellent language for performing information analysis, owing to the fantastic biological system of information-driven python packages. Pandas is one of those packages that make taking in and breaking down data much more accessible. The vast majority of the information for examination is accessible as a plain configuration, for example, Excel and Comma Separated files(CSV). To get information from CSV documents, we require a capability read_csv() that recovers information as an informal outline. Prior to utilizing this capability, we should import the pandas library.
Importing Pandas library:
import pandas as pd
The read_csv() capability is utilized to recover information from CSV record. The grammar of the read_csv() technique is:
pd.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None,usecols=None,squeeze=False,prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False,skiprows=None,nrows=None,na_values=None,keep_default_na=True,na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False,keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None,dialect=None,tupleize_cols=None,error_bad_lines=True,warn_bad_lines=True,skipfooter=0,doublequote=True,delim_whitespace=False,low_memory=True, memory_map=False, float_precision=None)- filepath_or_buffer: It is the area of the document, which is to be recovered utilizing this capability. It acknowledges any string way or URL of the record.
- Sep: It denotes a separator, the default being ',' like in CSV (comma isolated values).
- Header: It acknowledges int, the rundown of int, and line numbers to use as the section names and beginning of the information. In the event that no names are passed, i.e., header=None, it will show the first section as 0, the second as 1, etc.
- Use cols: It is utilized to recover just chosen sections from the CSV document.
- nrows: It implies the number of lines to be shown from the dataset.
- index_col: If None, there are no list numbers shown alongside records.
- Squeeze: If valid and just a single segment is passed, returns pandas series.
- Skip rows: Skips passed lines in new information outline.
- Names: It permits recovery sections with new names.
| Parameters | Use |
| filepath_or_buffer | The file's URL or directory location |
| sep | The default separator is ',' like in csv. |
| index_col | Instead of 0, 1, 2, 3...r, the passed column is used as an index. |
| header | Makes the given row/s[int/int list] into a header. |
| Use_cols | To create a data frame, just the given col[string list] is used. |
| Squeeze | If true and only one column is given, pandas series is returned. |
| skiprows | Skips previous rows in the new data frame |
Recovering information from csv document
# Import pandas
import pandas as pd
# reading csv file
pd.read_csv("data.csv")Read CSV file into DataFrame
df = pd.read_csv('data.csv')
print(df)Output
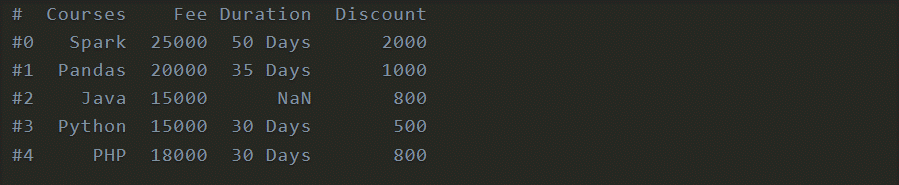
You can set a section as a file utilizing index_col as param. This param takes values {int, str, grouping of int/str, or False, discretionary, default None}.
df = pd.read_csv('data.csv', index_col='Courses')
print(df)
Output
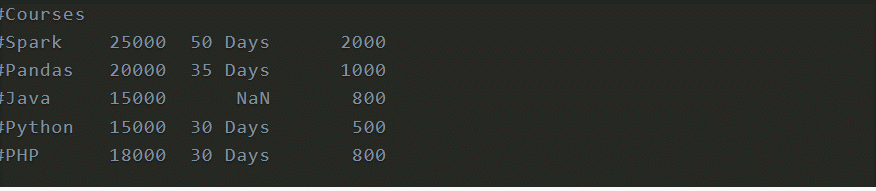
On the other hand, you can utilize file/position to indicate the section name. At the point when utilized a rundown of values, it makes a MultiIndex.
Skiping rows
At times you might have to skirt first-line or skip footer columns, use skiprows and skipfooter param individually.
df = pd.read_csv('data.csv', header=None, skiprows=2)
print(df)
Output

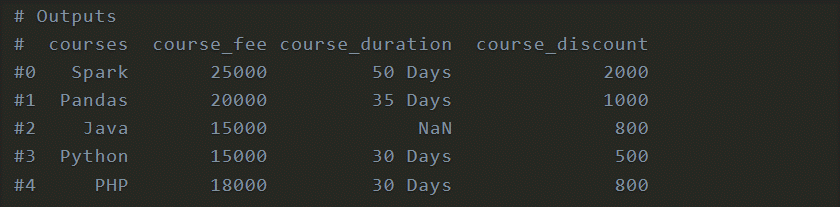
Peruse CSV by Ignoring Column Names
As a matter of course, it considers the principal line from succeeding as a header and involves it as DataFrame section names. In the event that you need to consider the main line from succeeding as an information record, use header=None param and use names param to determine the section names.
Not determining names brings about section names with mathematical numbers.col = ['courses','course_fee','course_duration','course_discount']
df = pd.read_csv('data.csv', header=None,names=col,skiprows=1)
print(df)Output
Loading only the selected columns
Utilizing usecols param you can choose sections to stack from the CSV record. This accepts segments as a rundown of strings or a rundown of int.
col = ['courses','course_fee','course_duration','course_discount']
df = pd.read_csv('data.csv', usecols =['Courses','Fee','Discount'])
print(df)
Output

Setting Data Types to Columns
As a matter of course read_csv() relegates the information type that best fits in view of the information. For instance Fee and Discount for DataFrame is given int64 and Courses and Duration are given string. How about we change the Fee sections to drift type.
df = pd.read_csv('data.csv', dtype={'Courses':'string','Fee':'float'})
print(df.dtypes)Output

Parameters of pandas read_csv()
- nrows - Specify the number of lines to peruse.
- true_value - What are all qualities to consider as True?
- false_values - What are all qualities to consider as False?
- mangle_dupe_cols - Duplicate segments will be indicated as 'X', 'X.1', … 'X.N', as opposed to 'X'… 'X'.
- Converters - Provide a Dict of the values that have to be changed.
- skipinitialspace - Similar to right manage. Skips spaces after the separator.
- na_values - Specify all qualities to consider as NaN/NA.
- keep_default_na - Specify whether to stack NaN values from the information.
- na_filter - Determine any missing characteristics. To improve execution, set this to False.
- skip_blank_lines - Avoid blank lines that lack information.
- parse_dates - Specify how you need to parse dates.
- Thousands-Separator for thousand.
- Decimal - Character for the decimal point.
- lineterminator - Line separator.
- quotechar - Use statement character when you need to consider delimiter inside a worth.
Other than these, there are a lot more discretionary params, allude to pandas documentation for subtleties.