Standard Scaler in SKLearn
- The sci kit learns in python is a library thatch is used in machine learning which is used to work on data modeling.
- It is only focused on the data modeling, it does not focus on manipulation and loading of the data.
- The classification, clustering through constancy interface, and regression are the modeling.
Uses of SK learn
- The main use of scikit learn in python is that it is open source.
- The benefit is:
- Open source
- Versatile used
- Free
- Easy to use
- Properly documented
Open source:
- The SK learn is a library that is open source and publicly available.
- Anyone can use this library and can modify the code.
Versatile used:
- The SK learn is a library that is used for many things like can identify user actions.
- Customer behaviour is also predicted which shows the versatile nature.
- SK learn library is user-friendly and comes with many tools.
Free:
- The SK learn is a library, which people use for free and any license for running is not necessary
Easy to use:
- The SK learn is a python library that people can access the library at any time.
- It is mostly used by research organizations for their operation since SK learn is easy to use.
Properly documented:
- The SK learn is a python library in which documentation is used properly.
- It contains API documentation which is accessible from the website provided.
Advantages of SK learn
- It is user-friendly and can do many things like can identify user actions.
- It is free to use.
- It is easy to use.
- It provides API documentation for the user.
- Here the documentation is done properly.
- The contributor updated the SK learn library done by the international community.
- It is spread for the BSD license which means it can used without restriction.
Disadvantages of SK learn
- It is not much of use for in-depth learning.
Let us consider an example to see the working of the SK learn library:
from sklearn.cluster import kmeans_plusplus
from sklearn.datasets import make_blobs
import matplotlib.pyplot as pl
/ / here sample means it is used to generate sample data
sample = 5000
component = 4
/ / kmeans_plusplus which is used to seed calculate from k
a, b_true = make_blobs( n_samples = sample,centers = component, cluster_std = 0.60, random_state = 0 )
a = a[ : , : : -1]
centers_init, indices = kmeans_plusplus(a, n_clusters = 4, random_state = 0)
/ / plot figure means it is used for seed plotting on the screen
plot.figure(1)
colors =["red", "blue", "green", "yellow"]
for k, col in enumerate(colors):
cluster_data = b_true == k
plot.scatter( a [cluster_data, 0], a [cluster_data, 1], c=col, marker=".", s=10)
plot.scatter(centers_init[:, 0], centers_init[:, 1], c="b", s=50)
/ / plot tile is used to give the title for the graph on the screen
plot.title("K-Mean Clustering")
plot.xticks([])
plot.yticks([])
plot.show()output:
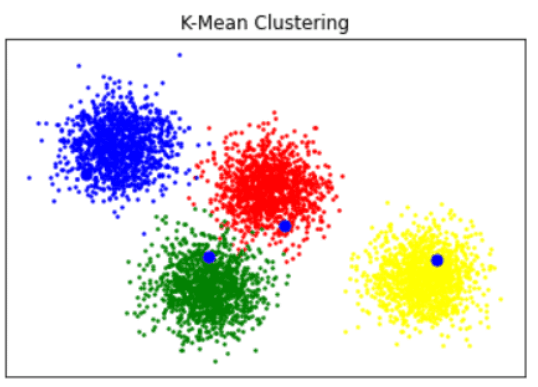
Installing the SK learn:
- SK learn is used to model the data.To install the SK learn library we need to install scipy and numpy.
- Command to install the numpy is:
pip install numpy - After execution of the above command, we can see the numpy is installed.
- After numpy is installed we need to install scipy. We can install scipy using the following command.
pip install scipy - After execution of the above command, the scipy is installed. After both libraries are installed. We can install scikit library using the following command:
pip install scikit-learn - If the SK learn is already installed then no need to install them again.
- We can update the SK learn using the following command:
pip install -u scikit-learn
SK learn features: - We know that SK learn is used to model the data but not to manipulate the data.
- The following are the features of SK learn:
Supervised learning: - It is a predictive model, in which data comes with good quality which we want to predict.
- It is divided into two types:
- Classification:
- if the problem output has been categorized into “white”, and”black” then the problem is considered to be a classification problem.it is a predictive model in which the set data is categorized into classes.
- Regression:
- If the problem output is continuous output then the problem is considered to be a regression problem. Examples are “kilometers”.
- Classification:
Dimension reduction:
- In mathematics the dimension has measured the distance and size of the object.
- We can reduce the number of input features from the set using dimension reduction which is predictive modelling.
Cross-validation:
- The cross-validation is used to make sure that the model is accurate since predictive modeling is done by supervised learning.
- It is used to predict data of the predictive modeling.
Open source: - The program code is freely available or anyone can access it since it is open source.
- The user can not only access but also can modify the code since is made for public use.
Feature selection:
- The SK learn is used to select the features from the set.
- The predictor object that is used by the made is used to tunning down.
- The supervise model is used to recognize the attribute.
Ensemble methods:
- The machine learning technique is used to combine many models which is turned intothe predictive model, this model is called the ensemble model.
- In other words we call consider it as the combination of prediction of models.
Clustering: - The problem in which we want to find the inherent is called the clustering problem.
- Grouping the customers by their behaviour which is permanent.
Unsupervised learning: - It does not provide any guidance and does not provide any superior. here the labels are not present for data.
- For a variable x there is no output respectively since there is no superior.
- Here the model is needed to allowed to work on own data.