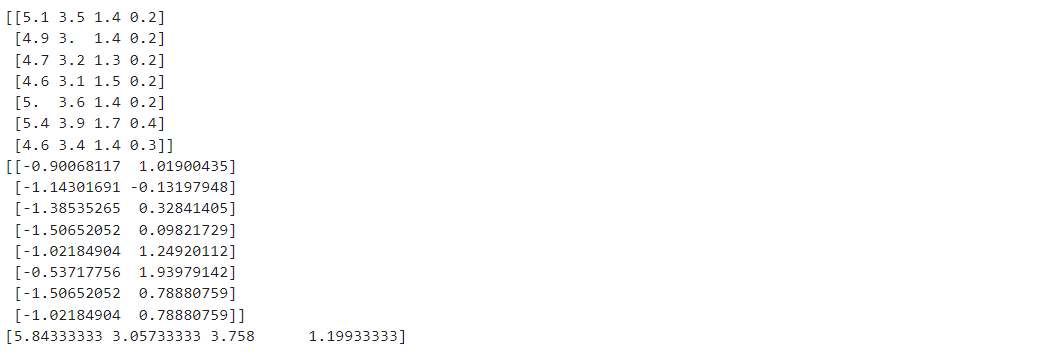StandardScaler in Sklearn
When and How Should You Use StandardScaler?
StandardScaler comes into play whenever the properties of the provided dataset change significantly within their ranges or are recorded in different measurement units.
Since using StandardScaler to lower the average to 0, the data are scaled to have a variance of 1. Unfortunately, extreme values within the data have a significant impact on determining the empirical mean and standard deviation of the data, which reduces the range of characteristic values.
Those changes within initial characteristics could cause problems for so many methods of machine learning. If a dataset's feature has values with wide or drastically diverse ranges, that specific feature of the dataset will govern the distance computation using algorithms that compute distance.
The sklearn StandardScaler function is based on the concept of variables within a dataset with values spanning a number of ranges that may not contribute evenly to the model's fit parameters and training function and may even generate bias in the model's predictions.
Therefore, before including the features in the machine learning model, we must normalise the data (= 0, = 1). To overcome this possible problem, feature engineering standardization is frequently used.
Using Sklearn to standardise
sklearn.preprocessing.StandardScaler(*, copy = True, with_mean = True, with_std = True)
By eliminating the mean from the features and scaling them to a unit variance, properties were normalised using this technique.
The formula for determining a feature's standard score is z = (x - u) / s, where u is the mean of the training feature (or zero if mean = False) but also s is the sample standard deviation (or one if std = False).
Using the relevant data on the characteristics in the training dataset, primary character and scaling are applied separately to each feature. The fit() function then retains the mean and standard deviation for use with further samples using transform().
Parameters
1. copy: Make an effort to prevent duplicates whether this option is set to True and scale the samples directly. If the input is not a NumPy array or scipy.sparse CSR matrix, for example, that is not always guaranteed to work in place. The function may still produce a duplicate given a sparse CSR matrix.
2. with_mean: Scale the data after centering it if the option is set to True. This doesn't work when applied to sparse matrices (and raises an exception), as centering them requires the creation of a compact matrix, which is often considered too large to fit in the ram under normal use conditions.
3. with_std: When enabled, this option transforms the incoming data to conform to the unit variance (or we can say it makes unit standard deviation). If this is the case, scale the data to unit variance (or equivalently, unit standard deviation).
Attributes
1. scale_: The data is proportionally scaled for each feature, with a zero mean and unit variance.
2. mean_: represents the median value for each feature inside the training sample. This value equals None if the mean parameter is set to False.
3. var_: It represents the variance of each feature in the training dataset. It is employed to establish the features' scale. This value equals None when the std argument is set to False.
4. n_features_in_: The number of features discovered during fitting is provided by this characteristic. The number of characteristics visible during fit.
5. feature_names_in_: The characteristics recognized by names during fitting make up this property. Only when X's feature names are string datatypes is X considered to be defined.
6. n_samples_seen_: This indicates how many samples every feature's estimate looked at.
StandardScaler Example
You need to first import the necessary libraries, import the Sklearn package to utilize the StandardScaler function.
The iris dataset will then be loaded. The sklearn.datasets package contains the IRIS dataset, which we may import.
We'll construct a StandardScaler class object.
Both independent and target traits are separated.
Applying the transformation to the dataset would involve using the fit transform() method.
Syntax:
object_ = StandardScaler()
object_.fit_transform(features)Following the above approach, we first created an instance of the StandardScaler() function. We standardize the data by combining the supplied object with fit transform().
Program:
# Data standardization with Python
# The necessary library is being imported
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# The dataset is loaded
X, Y = load_iris(return_X_y = True)
# 3 rows of the original data are printed
print(X[:7, :6])
# The process of making a StandardScaler class object
std_scaler = StandardScaler()
# 3 rows of the modified data are printed.
print(std_scaler.fit_transform(X)[:8, :2])
print(std_scaler.mean_)
Output: