Artificial intelligence mini projects with source code in Python
Project Name: Movie recommendation system
A recommendation provides customers with relevant information related to their searches. Before the recommendation system, the most common method of purchasing was to rely on the advice of friends. However, based on your search history, viewing history, or purchase history, Google now knows what news you'll read, and YouTube knows what kinds of videos you'll watch.
A recommendation system aids a firm in gaining loyal clients and establishing confidence by providing them with the items and services for which they come to your website. Today's recommendation systems are so sophisticated that they can manage even new customers who are visiting the site for the first time. They can also recommend things that are currently trending or highly rated. For this project, you can use content-based filtering.
Content-based filtering
The algorithm suggests a product that is like those that were previously viewed. To put it another way, we're trying to locate items that seem alike in this algorithm. If a person enjoys watching Sachine Tendulkar's shots, he might also enjoy watching Ricky Ponting's shots because the two videos have comparable tags and categories. Only the material appears to be identical, and it does not place a greater emphasis on the viewer. Only the product with the greatest score based on previous preferences is recommended.
Dataset
Link: - https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata?select=tmdb_5000_movies.csv .
Tech stack
- Python
- Pandas
- Streamlit
- NLTK
- Pickle
- Requests
Data processing
We need to select the features which play key role in recommendation. The data selected must be analyzed and preprocessed. We are not going to use all the feature columns. We will only select those that will play a major part in recommendations.
Stemming
- Porter Stemming is used to perform stemming operations on a tag's column. Python's nltk package is used for this.
- Stemming is the process of stripping a word down to its root, or lemma, which attaches to suffixes, prefixes, or the roots of other words. For instance, a stemming algorithm changes the phrases "To the root word "chocolate," "chocolates," "chocolatey," and "Choco," and to the stem "retrieve," "retrieval," "retrieved," and "retrieves," respectively. "COSINE
Cosine similarity
- Cosine Similarity is a machine learning technique which measures the similarity between two vectors. By applying the cosine operation to the angles between the vectors, we can perform this cosine similarity.
- It is majorly used to find out similarity and classify text information
Creating vectors
Based on the tag’s column, create vectors for corresponding movies, and then use cosine-similarity to compute the distance. Regardless of size, cosine similarity is a statistic for assessing how similar papers are. It determines the cosine of the three-dimensional angle created by two vectors projected side by side. Two comparable texts that are separated by the Euclidean distance because of the size of the document are likely to be oriented closer to one another because of the cosine similarity. Smaller the angle higher will be the similarity.
Source code of the program
import numpy as np
import pandas as pd
import ast
movies = pd.read_csv('tmdb_5000_movies.csv')
credits = pd.read_csv('tmdb_5000_credits.csv')
movies = movies.merge(credits,on='title')
movies = movies[['movie_id','title','genres','overview','keywords','cast','crew']]
movies.head()
movies.isnull().sum()
movies = movies.dropna()
movies.duplicated().sum()
def convert(obj):
L= []
for i in ast.literal_eval(obj):
L.append(i['name'])
return L
movies['genres'] = movies['genres']. apply(convert)
movies['keywords'] = movies['keywords']. apply(convert)
def convert3(obj):
iteration = 0
L= []
for i in ast.literal_eval(obj):
if (iteration! =3):
L.append(i['name'])
iteration = iteration+1
else:
break
return L
movies['cast'] = movies['cast']. apply(convert3)
movies.head()
def extract_director(obj):
L= []
for i in ast.literal_eval(obj):
if(i['job’] = ='Director'):
L.append(i['name'])
break
return L
movies['crew'] = movies['crew']. apply(extract_director)
movies.head()
movies['overview'] = movies['overview'].apply(lambda x:x.split())
movies.head()
movies['genres'] = movies['genres'].apply(lambda x:[i.replace(" ","")for i in x])
movies['keywords'] = movies['keywords'].apply(lambda x:[i.replace(" ","")for i in x])
movies['crew'] = movies['crew'].apply(lambda x:[i.replace(" ","")for i in x])
movies['cast'] = movies['cast'].apply(lambda x:[i.replace(" ","")for i in x])
movies.head()
movies['tags'] = movies['overview'] + movies['genres'] + movies['keywords'] + movies['cast'] + movies['crew']
movies.head()
New_Data = movies[['movie_id','title','tags']]
New_Data.head()
New_Data['tags'] = New_Data['tags'].apply(lambda x:" ".join(x))
New_Data.head()
New_Data['tags'] = New_Data['tags'].apply(lambda x:x.lower())
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features=5000,stop_words='english')
cv.fit_transform(New_Data['tags']).toarray().shape
vectors = cv.fit_transform(New_Data['tags']).toarray()
vectors
cv.get_feature_names()
import nltk
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
def stem(text):
y = []
for i in text.split():
y.append(ps.stem(i))
return " ".join(y)
New_Data['tags'][0]
New_Data['tags'] = New_Data['tags'].apply(stem)
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(vectors)
similarity[1]
sorted(list(enumerate(similarity[0])),reverse=True,key=lambda x:x[1])[1:10]
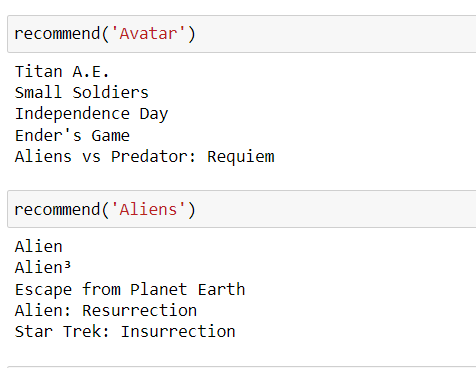
def recommend(movie):
movie_index = New_Data[New_Data['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)),reverse=True,key=lambda x:x[1])[1:6]
for i in movies_list:
print(New_Data.iloc[i[0]].title)
recommend('Avatar')
Output