Python Memory Management
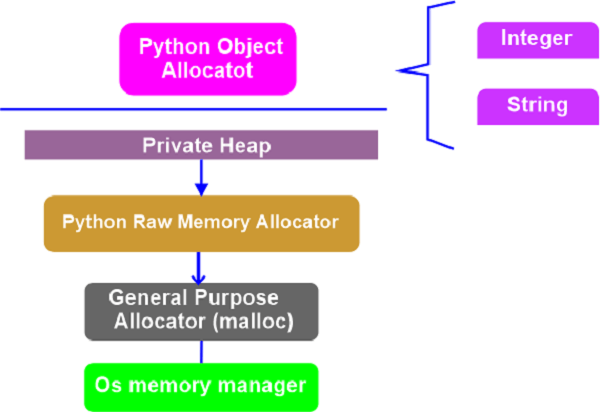
In order to manage memory, Python uses a private heap that contains all of its data structures and objects. The Python memory manager is responsible for the internal management of the private heap. Different parts of the Python memory manager deal with different aspects of dynamic storage management, such as sharing, segmentation, preallocation, or caching.
We will gain a better understanding of some of Python's behaviors if we are familiar with its internal workings. I hope we will also develop a new interest in Python. There is a lot of logic running in the background to make sure our program performs as we anticipate.
Considering Memory as an Empty Book:
Start by visualizing a computer's memory as a blank book meant for short stories. The pages are blank at this time. Different writers will eventually emerge. Each author wants a little room to write their story. They have to be careful which pages they have to write on because they can't write on top of one another. They speak with the book's manager before they start writing. The manager then decides where they are permitted to write in the book.
This book has been around for a very long time, so many of the stories in it are outdated. The stories are taken down to make room for new ones when no one reads them or makes any references to them.
Computer memory is analogous to that blank book, in essence. This analogy works pretty well because fixed-length contiguous blocks of memory are frequently referred to as pages.
The authors can be compared various programs or processes that require memory to store data. The manager serves as a kind of memory manager by determining where the authors can write in the book. The garbage collector is the one who takes out the old stories to make room for the new ones.
Memory Management: Hardware and Software
Applications read and write data using memory management. Where to store the data for an application is decided by a memory manager. The manager must locate some free space and provide it to the application because memory is limited, similar to the book's pages. Memory allocation is the general term used to refer to this memory provisioning process.
On the other hand, data can be deleted or released when it is no longer required.
When we run our Python programs, a physical device inside of our computer stores data. Before the objects actually reach the hardware, the Python code must pass through several levels of abstraction.
The operating system is one of the primary layers just above hardware (like a Hard drive or RAM). Requests to read and write the memory are carried out or get rejected.
Applications sit on top of the OS, with the default Python implementation being one of them (included in our OS or downloaded from python.org.) The Python application manages the memory used by our Python code. This article focuses on the memory management algorithms and structures used by the Python application.
Python's default implementation:
In reality, CPython, the default Python implementation, is created in the C programming language. A language with written characters from another language is really awesome. An English-language reference manual contains a definition of the Python language. That manual alone, though, isn't all that helpful. We still require a means of decoding written code based on the manual's rules.
To actually run interpreted code on a computer, we also need something. Both of these requirements are satisfied by the standard Python implementation. Our Python code is transformed into instructions, which are then executed on a virtual machine.
Python is known as an interpreted programming language. Our Python code is actually reduced to bytecode, which is a more readable form of instruction for computers. When we run our code, a virtual machine decodes these instructions.
Have we ever come across an a.pyc file or a folder called "pycache". That is the bytecode that the virtual machine interprets.
It's significant to remember that CPython is not the only implementation available. For use with Microsoft's Common Language Runtime, IronPython is compiled down. In order to run just on Java Virtual Machine, Jython is translated into Java bytecode. Then there is PyPy, but we won't go into detail about that because it deserves its own entire article. We will concentrate on how Python's default implementation, CPython, handles memory management for the purposes of this article.
Okay, so CPython interprets Python bytecode and is written in C. The memory management structures and algorithms are present in the C code for CPython. We must gain a fundamental understanding of CPython in order to comprehend how Python manages its memory.
C, the language used to create CPython, does not come with native support for object-oriented programming. The CPython code contains a lot of intriguing designs as a result.
Everything within Python is an object, including types like int and str, as we may have heard. In CPython, it's accurate in terms of implementation. Every other object in CPython utilizes a struct called a PyObject.
The PyObject, the ancestor of all Python objects, only has two components:
- ob_refcnt: reference count
- ob_type: pointer to another type
For garbage collection, references are counted. The real object type is then indicated by a pointer. That object type simply describes a Python object using another struct (such as a dict or int).
Each object has a unique memory allocator that is only capable of allocating memory for that particular object. Additionally, each object has a memory deallocator that "frees" the memory when it is no longer required.
All this discussion of allocating and freeing memory, though, is missing one crucial element. On a computer, memory is a shared resource, and if two processes attempt to write to the same location simultaneously, bad things may result.
The Global Interpreter Lock (GIL):
The GIL offers a solution to the frequent issue of managing shared resources, such as computer memory. Two threads may step on each other's toes if they attempt to modify so same resource at the same time. Both threads may end up with the opposite of what they intended in the final product, which can be a jumbled mess.
Think about the book analogy once more. Let's say that two writers decide obstinately that it is their turn to write. Additionally, they must both write simultaneously on the same page of the book.
They both start writing on the page while ignoring each other's attempts to tell a story. Two stories are ultimately stacked on top of one another, rendering the entire page completely illegible.
A single, global lock on the interpreter whenever a thread interacts with the shared resource is one approach to solving this issue (the page in the book). To put it another way, just one author can be writing at once.
By getting locked the entire interpreter, Python's GIL achieves this, making it impossible for a different thread to trample over the active one. CPython makes use of the GIL to ensure the safe handling of memory. This strategy has advantages and disadvantages, and the GIL is hotly contested within the Python community.
Garbage Collection:
Let's go back to the book analogy and say that some of the stories are getting very old in the book. No longer are those stories read or used as references. You could get rid of something to make space for fresh writing if no one is reading it or using it in their own works. That old, unsourced writing is comparable to a Python object with a reference count of 0. Keep in mind that each Python object has a reference count and a pointer to its type.
There are several reasons why the reference count rises. If we assign the reference count to another variable, for instance, it will rise:
num = [1, 2, 3]
# Reference count is 1
more_numbers = num
# Reference count is 2
Additionally, it will rise if we use the thing as an argument:
total = sum(num)
The reference count will rise if we include the object in a list, as in the following final example:
matrix = [num, num, num]
The sys module in Python enables us to view an object's current reference count. We can use sys.getrefcount(numbers), but be aware that doing so adds 1 to the reference count because the object is added when using getrefcount().
In any case, the object's reference count is higher than 0 if it is still needed to remain in our code. The object does have a specific deallocation function that is called once it drops to 0, "freeing" the memory for use by other objects.
What other objects use the memory that has been "freed," and what does that mean exactly? Let's get started with CPython's memory management right away to learn more about it.
Memory Management in CPython:
Let's focus on CPython's memory architecture and algorithms. CPython's memory management uses Data structures and algorithms to manage our data which is very important.
As previously mentioned, there are several abstraction layers between the physical hardware and CPython. Applications (which include Python) can access the virtual memory layer that is created by the operating system (OS), which abstracts the physical memory. A portion of memory is set aside by an OS-specific virtual memory manager for the Python process. The Python process now owns the darker grey boxes in the image below.
Python uses non-object memory and a chunk of the memory for internal use. The remaining space is used for object storage (dict, your int, and the like). Please be aware that this was a bit simplified. Evaluate the CPython source code, where all of this memory management takes place, for a complete picture.
The task of allocating memory in the object memory space is carried out by an object allocator in CPython. The majority of the magic takes place in this object allocator. It is called whenever a new object needs to be deleted or allocated space.
For Python objects like int and list, adding and removing data typically doesn't require a lot of data at once. As a result, the allocator's design has been adjusted so that it can handle small amounts of data at once. Additionally, it tries to wait until memory allocation is absolutely necessary.
The allocator is described as a quick, special-purpose memory allocator for smaller chunks to be used on top of a general-purpose "malloc" in the source code comments. The memory allocation library function for C in this instance is called malloc.
We'll now examine CPython's memory management approach. We'll first discuss the three main components and how they correspond to one another. Arenas are the biggest memory blocks and are positioned on a page boundary. An OS-used fixed-length contiguous chunk of memory's edge is referred to as a page boundary. Python makes the 256-kilobyte page size assumption for the system.
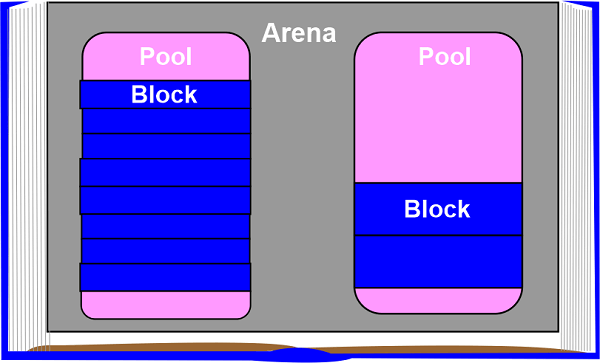
Pools, which are of one virtual memory page (four kilobytes), are found within the arenas. These resemble the pages in our analogous book. These pools are divided up into smaller memory blocks.
Each block in a specific pool belongs to the same "size class". Given a certain amount of requested data, a size class defines a particular block size. The graph below was directly extracted from the comments in the source code:
| Request in bytes | Block size allocated | Size class IDX |
| 1-8 | 8 | 0 |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| ...so on | ... | ... |
| 497-504 | 504 | 62 |
| 505-512 | 512 | 63 |
For instance, if 34 bytes are needed, the data will be stored in a block of size 40 bytes.
Pools:
Pools are made up of blocks that belong to the same size class. Every pool keeps a double-linked list of all the other pools in its size class. Thus, even across various pools, the algorithm can quickly locate space that is available for a given block size.
A usedpools list keeps track of all the pools for each size class that still have some data space available. The algorithm checks this usedpools list from the list of pools for a given block size when that block size is requested.
Pools themselves have to be in one of the three states: used, full, or empty. Blocks that are available in a used pool can be used to store data. Blocks in a full pool are allotted and have data in them. When required, any block size class can be assigned to an empty pool, which has no data stored.
All the pools that are currently empty are tracked by a freepools list.
Assume that an 8-byte memory block is required by our code. A new, empty pool is created and initialized to store 8-byte blocks if there are no pools in the used pools of the 8-byte size class. The usedpools list is then updated to include this new pool, making it accessible for incoming requests.
A full pool, for example, might release some of its blocks because the memory is no longer required. The usedpools list for that size class would be updated to include that pool once more. We can now see how this algorithm allows pools to freely have a transition between these states (or even memory size classes).
Blocks:
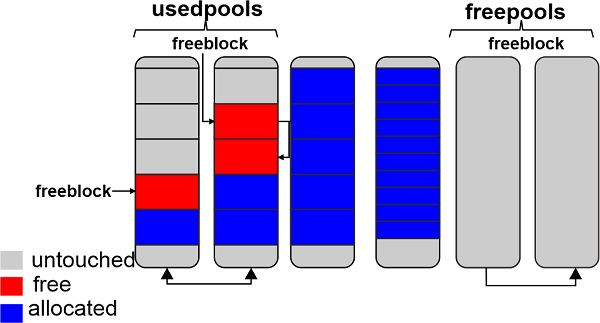
Pools constitute a pointer to their "free" memory blocks, as shown in the diagram above. There is a slight variation in how this operates. The comments in the source code state that this allocator "strives at all stages (pool, arena, and block) never make contact a piece of memory until it's actually needed."
Thus, a pool may contain blocks in any one of three states. These states fit the following definition:
- Untouched: memory that has not been allocated
- free: memory that was made available but later declared "free" by CPython because it no longer contains important information
- allocated: a space in memory that is actually used to store important information.
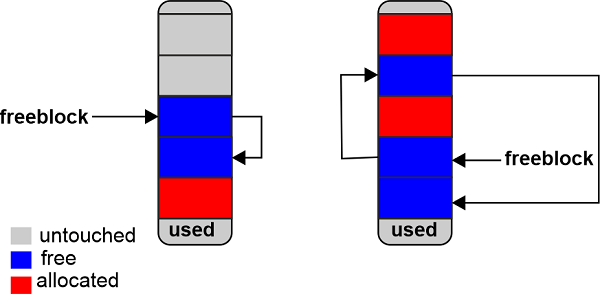
A singly linked list of free memory blocks is referenced by the free block pointer. In other words, a list of places where data can be stored. The allocator will receive some untouched blocks from the pool if more is required than the free blocks that are currently available.
Blocks that are now "free" are added to the forefront of the free block list as the memory manager makes them so. The actual list might not be made up of consecutive memory blocks, as shown in the first delightful diagram. It might resemble the illustration below:
Arenas:
Pools are found in arenas. Those pools could be filled, empty, or in use. However, compared to pools, arenas don't have as many explicit states.
Instead, a doubly linked list termed usable arenas is used to organize arenas. According to how many free pools are available, the list is arranged. The arena is located nearer the top of the list, the fewer free pools there are.
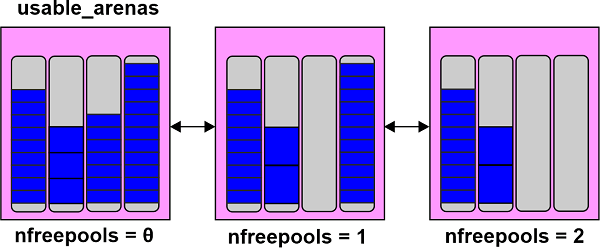
This implies that new data will be added to the arena that already contains the most data. Why not, though, do the opposite? Why not store data in the location with the most space?
This introduces the notion of memory that is actually free. We will notice that I frequently use the word "free" in quotation marks. The cause is that, even though a block is marked as "free," the operating system never actually receives that memory back. The Python process reserves it and will use it in the future for fresh data. When memory is actually freed, the operating system can once again use it.
The only things that can surely be freed are arenas. Therefore, it makes sense to allow those arenas that really are close to being empty to do so. In this manner, the memory usage of our Python program as a whole can be decreased, and that portion of memory can actually be freed.
The ability to manage memory is essential for using computers. For better or worse, Python manages nearly all of it in the background. Many of the tedious details of working with computers are abstracted away by Python. This gives us the freedom to develop our code at a higher level without having to stress about where and how all those bytes are being stored.