Working with CSV files in Python
Python is an Object-Oriented high-level language. Python has an English-like syntax, which is very easy to read and write codes. Python is an interpreted language which means that it uses an interpreter instead of the compiler to run the code. The interpreted language is processed at the run time thus takes less time to run. Python is also interactive, so we can directly run programs in the terminal itself.
While working in Python, many times, we will need to read a CSV file and do some operations with the data inside it. The comma-separated files or CSV files are some of the most used files to store the data. In a CSV file, data is stored in a way that a comma separates every value, hence the name Comma-separated file. The first row denotes the column header. It is pretty common to work with CSV files in Python, and one should have a knowledge of how to deal with them. We can work with CSV by using the CSV library in Python. Another option is using pandas which is a very powerful library and is very useful in many applications.
An example of a CSV file is:
Id, Name, Age
1, Rahul,21
2, Michael,22As you can see, the first row denotes the column heading, and a comma separates the data. Here the delimiter is a comma, and we can define any single character as a delimiter in a CSV file.
In this post, we are going to use the CSV library in python to work with CSV files. It provides the functionality of both reading and writing the CSV files with some other functionalities also.
Reading CSV Files
We can read the CSV file by using CSV.reader() function. First, open the CSV file as text with the open() function and pass the reader object to it. Let us see this with an example. Suppose we have a file named SampleData.csv.
Code:
import csv
count = 0
with open('SmpleData.csv, 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
count = count+1
if(count == 5):
breakOutput:
['Sale ID', 'Salesperson', 'First Name', 'Last Name', 'VIP', 'Date of Birth', 'Gender', 'Country', 'Item Quantity', 'Item Price', 'Item Colour', 'Item Size', 'Item Range', 'Item COGS', 'Item Profit', 'PurchaseDate']
['1', '8', 'Denver', 'Roos', 'Y', '29/06/1941', 'M', 'Australia', '3', '17.79', 'COLOUR-WHITE', 'SIZE-M', 'RANGE-OTHER', '12.6309', '5.1591', '23/01/2014']
['2', '1', 'Madie', 'Tyson', 'Y', '21/03/1985', 'F', 'Australia', '3', '165', 'COLOUR-WHITE', 'SIZE-M', 'RANGE-JACKET', '108.9', '56.1', '14/12/2013']
['3', '2', 'Raymond', 'Jelis', 'N', '23/08/1937', 'M', 'United Kingdom', '4', '658', 'COLOUR-BLUE', 'SIZE-XXL', 'RANGE-PANT', '572.46', '85.54', '10/01/2014']
['4', '7', 'Raquel', 'Hess', 'N', '6/08/1975', 'F', 'Australia', '9', '98.55', 'COLOUR-BLACK', 'SIZE-S', 'RANGE-JACKET', '61.101', '37.449', '15/10/2013']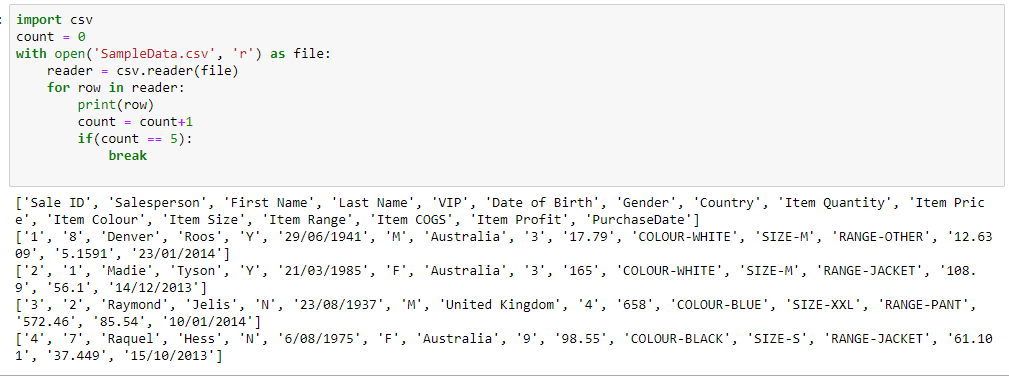
In the above program, we have used a SampleData.csv file. You can download any CSV you want. Run this code with the file in the same directory.
Let us try to understand the code now:
First of all, we have imported the library to work with a CSV file which is CSV. Since the file we are using contains thousands of rows, we want to print only 5, so we have declared the variable count to keep track of rows printed. After that, let us understand the code line by line:
• with open('SmpleData.csv, 'r') as file:
reader = CSV.reader(file)In this code, we have opened the file in reading mode by using the Python open() function. After this, we convert this file object into a reader object by using the reader function and save it in a variable.
• for row in reader:
(row)Since the reader object is iterable so we can loop it by using the for loop and print row one by one.
• count = count+1
if(count == 5):
breakIn these lines of code, we are just incrementing the count and breaking the loop when the count is five just to print the first five lines of the file.
Writing CSV files
We can also write a CSV file with the help of the CSV library in Python. We can write the CSV file using the writer object from CSV.writer() function. To create the data set to export into a CSV file, we must make a list for each row and add all of these rows in a single list. We will also need to define a list of just column headings. Then we pass this data to the CSV.writer() function that returns a writer object that converts the data to write in a CSV file. After that, we will use methods like writerows() to write data into a CSV file.
Let us see the code to write data into a CSV file:
import csv
headers = [“id”, “Name”, “Age”]
rows = [
[1, “Rahul”,21],
[2,”Michael”,22],
[3,”virat”,19]]
with open('students.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(headers)
writer.writerows(rows)When we run the above code, a students.csv file will be created in the current directory with the following content:
id, Name, Age
1, Rahul,21
2, Michael,22
3, Virat,19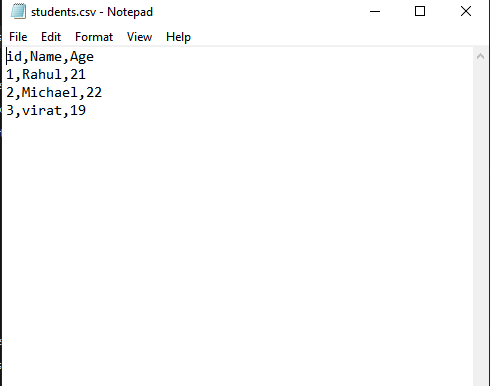
If we want to add rows one by one, we can use the method writerow().
Now let us understand the code we have just written:
• import csv
headers = [“id”, “Name”, “Age”]
rows = [
[1, “Rahul”,21],
[2,”Michael”,22],
[3,”virat”,19]]In this part of the code, we import the CSV moduleand define the headers and rows for the data. The headers contain the column heading, and rows are the data for those headings.
• with open('students.csv', 'w', newline='') as file:
writer = csv.writer(file)Here we are first opening the file in write mode, and the object is named a file. After that, we are passing the file object to CSV.writer() function, which will convert the file object to the CSV.writer object. We are saving this object as a writer.
• writer.writerow(headers)
writer.writerows(rows)Here in the first line of code, we are writing the headers with the writers method, and in the second line, we are writing rows since rows contain multiple lines of data, so the method used id writers.
Writing Dictionary to CSV files
We can write a Python dictionary to a CSV file by using the objects of csv.DictWriter() class. The syntax for the csv.DictWriter() class is:
csv.DictWriter(file, fieldnames)Here, the file is the file name where we want to write the dictionary, and fieldnames is the list of column heading describing the order in which data is present. The basic logic is similar to writing data in a CSV file, but here, instead of defining the rows, we have to define a list of a dictionary that contains the data to be written. Use the following code to write a dictionary to a CSV file:
import CSV
mydict =[{'branch': 'CSE', 'name': 'Nikhil', 'year': '4'},
{'branch': 'CSE', 'name': 'Rahul', 'year': '1'},
{'branch': 'IT', 'name': 'Michael', 'year': '2'},
{'branch': 'ECE', 'name': 'Sagar', 'year': '3'},
{'branch': 'ME', 'name': 'Roahan', 'year': '3'},
{'branch': 'EEE', 'name': 'Virat', 'year': '1'}]
fields = ['name', ‘branch’, 'year',]
with open(‘students_data.csv’, 'w') as file:
writer = csv.DictWriter(file, fieldnames = fields)
writer.writeheader()
writer.writerows(mydict)After running the code, a file called students_data.csv will get created in your current directory with the following content:
name,branch,year
Nikhil, CSE,4
Rahul,CSE,1
Michael, IT,2
Sagar, ECE,3
Rohan, ME,3
Virat, EEE,1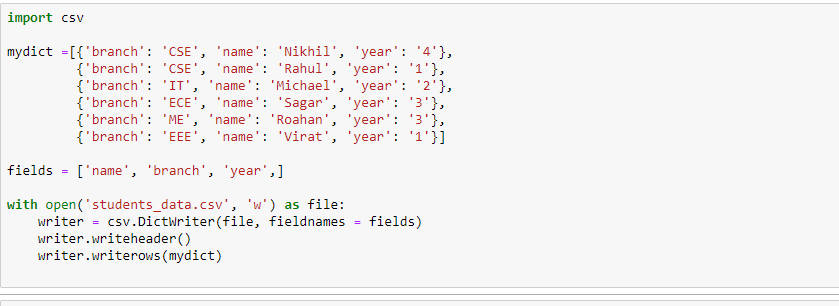
Now let us understand the code we have just written:
• import CSV
mydict =[{'branch': 'CSE', 'name': 'Nikhil', 'year': '4'},
{'branch': 'CSE', 'name': 'Rahul', 'year': '1'},
{'branch': 'IT', 'name': 'Michael', 'year': '2'},
{'branch': 'ECE', 'name': 'Sagar', 'year': '3'},
{'branch': 'ME', 'name': 'Roahan', 'year': '3'},
{'branch': 'EEE', 'name': 'Virat', 'year': '1'}]
fields = ['name', ‘branch’, 'year',]In this part of the code, we import the CSV moduleand define the dictionary, which contains all the data in a Python dictionary format, and the fieldname, which are nothing but column headings. These fieldnames define the order in which columns get written in a CSV file.
• with open(‘students_data.csv’, 'w') as file:
writer = csv.DictWriter(file, fieldnames = fields) Here we are first opening the file in write mode, and the object is named as the file. After that, we are passing the file object to CSVthe .writer() function, which will convert the file object to CSV.writer object, and the fieldnames are specified as an argument that contains the column headings. We are saving this object as a writer.
• writer.writeheader()
writer.writerows(mydict)Here in the first line of code, the writeheader method writes the first line of the file by using the given fieldnames arguments. In the second line, we are writing the dictionary to the file since rows contain multiple data lines, so the method used id writers.
Using Pandas to handle CSV
Most of the CSV reading, writing, and processing tasks can be easily done by using the CSV module in Python. If we have a lot of data to deal with and want to perform different operations to analyze data and restructure data, then using pandas is a far better option. The pandas library provides various methods to handle CSV files.
In this post, we will learn the basics of reading and writing a CSV file using pandas. Pandas is not a pre-defined library, so first, you have to install it from this link.
After successfully installing the pandas, it is the time to import them, we can import pandas by using the following code:
Import pandas as pdTo read the csv file using pandas, use the function read_csv()
import pandas as pd
data = pd.read_csv(“students.csv")Here, the program will load the file students.csv and save it into a variable called data. We can do further operations on the file by using this variable.
To write a new CSV file, use the function to_csv().
import pandas as pd
df = pd.DataFrame([[‘Rohan', 24], ['Rahul', 22]], columns = ['Name', 'Age'])
df.to_csv('person.csv')In the code above, first, we have defined a data frame that contains the columns heading and rows, and then we are exporting it to a file called person.csv.