Comparetoignorecase in Java
In Java, the function compareToIgnoreCase ( ) is part of the String class, which is part of the java.lang package. It is used to compare any two strings while disregarding lower- and upper-case distinctions. The technique compares strings by utilising the Unicode value of each character included in both texts. The way we supply both strings to the method compareToIgnoreCase ( ) is identical to how we pass both strings to the method compareTo ( ) , and the function returns the following results.
- If string 1 is longer than string 2 , a positive integer is returned.
- If string 1 is smaller than string 2 , a negative integer is returned.
- If string 1 and string 2 are equal , zero is returned.
public class CompareToIgnoreCase
{
public static void main ( String args [ ] )
{
String str1 = " Book ";
String str2 = " book ";
String str3 = " look ";
String str4 = " abc ";
String str5 = " BEEN ";
System.out.println ( str1.compareToIgnoreCase ( str2 ) ) ;
System.out.println ( str1.compareToIgnoreCase ( str3 ) ) ;
System.out.println ( str1.compareToIgnoreCase ( str4 ) ) ;
System.out.println ( str1.compareToIgnoreCase (str5 ) ) ;
}
}
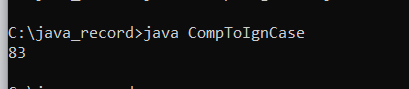
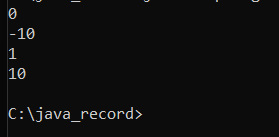
Explanation : Because we are using compareToIgnoreCase ( ) for string comparison , str1 and str2 are viewed as identical strings. As a result , the first output is 0.
For the second output , the string str1 ( " Book " ) is compared to the str3 ( " look " ) , and the distance between ' B ' and 'l' is 10 according to the alphabetical order ( case sensitiveness is ignored ). As a result, 'l' can be considered as 'L'). Because ' B ' comes after ' l , ' the answer is -10.
The character ' B ' is compared to the character ' a ' for the third output , and we know that the difference between ' B ' and ' a ' is 1. As a result , the output is 1.
" Book " is compared to " BEEN " for the fourth output. The first character of " Book " is compared to the first character of "Been," and the result is 0. So , we take the second letter of both strings ( ' o ' of " Book " and ' E ' of BEEN ) into account , and we observe that the difference between ' o ' and ' E ' is 10.0 Because ' o ' comes after ' E , ' the output is + 10.
In Java, we may also define our own compareToIgnoreCase() function. The method accepts two parameters, string str1 and string str2, and returns an integer. The following programme demonstrates this.
CompToIgnCase.java
public class CompToIgnCase
{
public int compToIgnCase ( String str1 , String str2 )
{
int i = 0 ;
int j = 0 ;
// converting strings to the
// lowercase to maintain case insensitivity
str1 = str1.toLowerCase ( ) ;
str2 = str2.toLowerCase ( ) ;
int cap1 = str1.length ( ) ;
int cap2 = str2.length ( ) ;
while (i < cap1 && j < cap2)
{
char c1 = str1.charAt ( i ) ;
char c2 = str2.charAt ( j ) ;
// if equal characters, proceed to next iteration
if (c1 == c2)
{
i = i + 1 ;
j = j + 1 ;
}
else
{
// The codePointAt ( ) function returns the Unicode of characters in this case,
// we are calculating the difference
// between Unicode of character
// at index I of string str1 and character at index j of string str2.
return (str1.codePointAt ( i ) - str2.codePointAt( j ) ) ;
}
}
// if all the characters of the strings and lengths are equal return 0
if (i == cap1 && j == cap2)
{
return 0;
}
if (i < cap1)
{
return cap1 – i ;
}
return (j - cap2) ;
}
public static void main ( String argvs [ ] )
{
CompToIgnCase object = new CompToIgnCase ( );
String str1 = " Book " ;
String str2 = " book " ;
String str3 = " look " ;
String str4 = " abc " ;
String str5 = " BEEN " ;
// invoking our own compToIgnCase ( ) method and displaying the result
System.out.println (object.compToIgnCase (str1 , str2) ) ;
System.out.println (object.compToIgnCase (str1 , str3) ) ;
System.out.println (object.compToIgnCase (str1 , str4) ) ;
System.out.println (object.compToIgnCase (str1 , str5) ) ;
}
}
Output :
To retain case insensitivity, all alphabets in both strings are transformed to lowercase letters (not in uppercase). The following example will help to clarify things.
CompToIgnCase.java
public class CompToIgnCase
{
// main method
public static void main(String argvs[])
{
String str1 = "6";
String str2 = "Book";
System.out.println(str1.compareToIgnoreCase(str2));
}
}
Output :
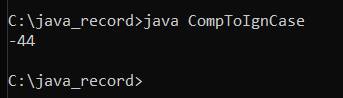
Explanation:
The Unicode value for ' 6 ' is 54 , while the value for ' B ' is 66 . As a result , the solution should be 54 - 66 = -12 . However , we receive -44 . Because the string " Book " is being transformed into " book , " and the Unicode value of ' b ' is 98 , this is the case. Thus , 54 - 98 equals -44 , as seen in the output. It demonstrates that the strings ' alphabets are changed into lowercase letters rather than uppercase letters . As a result , our custom compareToIgnoreCase ( ) function employs the toLoweCase ( ) method rather than the toUpperCase ( ) method.
When the first discrepancy is identified in the method compareToIgnoreCase ( ) , the comparison is terminated . It is seen from the first programme in this section, where " Book " is compared to " abc . " The first characters of each string are compared in this case, and we receive a mismatch . As a result , the remaining characters in both strings are ignored , and the comparison loop terminates to deliver the proper results .
When one of the strings has some extra characters and the remaining characters match the other string , simply the count of the extra characters is returned. Consider the following scenario .
CompToIgnCase.java
public class CompToIgnCase
{
// main method
public static void main ( String args [ ] )
{
String str1 = " Booksss " ;
String str2 = " Book " ;
System.out.println (str1.compareToIgnoreCase (str2 ) ) ;
}
}
Output :