What is Database Integrity?
Ensuring the correctness and consistency of data across its full life cycle is known as data integrity. It is essential to the planning, execution, and use of any system that handles, saves, or retrieves data. The word's connotations can vary greatly depending on the context, even within the broad category of computing, due to its extensive reach. While data integrity requires data validation, it is occasionally used as a stand-in for data quality.
Data corruption is the antithesis of data integrity. Ensuring that data is captured precisely as intended (e.g., a database rejecting mutually exclusive options correctly) is the general goal of all data integrity techniques. Additionally, it guarantees that the data is identical to what was originally recorded when it is retrieved later. The goal of data integrity is to stop accidental modifications to data. The discipline of safeguarding data from unauthorized parties is known as data security; it ought to be distinguished from data integrity.
Failure to retain information integrity refers to any unintentional modifications made to data as a result of a retrieval, transmission, or processing action. These include malevolent intent, unforeseen hardware failures, and human mistakes. Data security may have failed if unauthorized access was the cause of the modifications.
Depending on the type of data involved, this may show up as something as simple as a single photo or business-critical database being lost, or it could take the form of a tragic human death in a life-critical system or the appearance of a different colour in an image.
Categories of Integrity
Physical Soundness
Problems related to accurately storing and retrieving the data itself are addressed by physical integrity. Electromechanical failures, architectural defects, material aging, corrosion, blackouts of electricity, natural catastrophes, and other unique environmental risks, including ionizing radiation, very high or low pressure, g-forces, and extreme temperatures, are examples of challenges with physical integrity.
A clustered file system, storage arrays that compute parity calculations (like exclusive or use an encryption hash function), radiation-hardened chips, redundant hardware, uninterruptible power supplies, particular types of RAID arrays, error-correcting memory, and even the use of a watchdog timer on crucial subsystems are some of the techniques used to ensure physical integrity.
Error-correcting codes, sometimes referred to as error-detecting algorithms, are frequently heavily utilized in physical integrity. The Damm method and the Luhn algorithm are two examples of simpler tests and algorithms that are frequently used to identify human-induced data integrity problems. These are employed to preserve data integrity following manual transcription (such as financial card or bank route numbers) by a human intermediary from a single machine to another. Hashing functions can identify transcribing mistakes caused by computers.
Together, these methods provide varying levels of data integrity in production systems. A computer file system, for instance, may be set up on a tolerant of failure RAID array, but it might not include block-level checksums to identify and stop silent data corruption. As an additional illustration, a database management platform could adhere to the ACID characteristics, but the internal write cache of the hard drive or RAID controller might not.
Example:
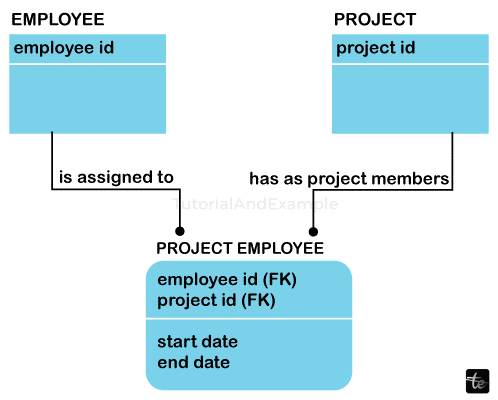
The link between related records as parents and children is an illustration of a data-integrity mechanism. The database automatically ensures the precision and authenticity of the data if a parent record maintains any number of related kid records. This prevents parents from losing their child records and ensures that a child record could exist without a parent, a condition known as orphaning. Furthermore, although a parent record is the owner of any child records, it guarantees that the parent record cannot be erased. Each application does not need to incorporate code integrity checks because everything is managed at the database level.
Logical Consistency
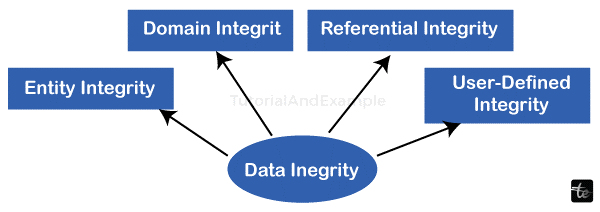
Regarding a specific piece of data, this kind of integrity is about whether or not it makes sense in the current context. Referential integrity, entity integrity, and the proper disregarding of impossible information collected by sensors in robotic systems are a few examples of issues covered in this.
These worries focus on making sure the information "makes sense" in light of its surroundings. Human mistakes, design defects, and software bugs are challenges. Program assertions, check obstacles, foreign key constraints, and other run-time validations of sanity are examples of common techniques used to guarantee logical integrity.
In addition to dealing with simultaneous demands to record and retrieve data the latter of which is a whole other topic physical and logical integrity frequently face similar difficulties, such as human mistakes and design defects. If a data sector's sole flaw is a logical fault, it can be recovered by deleting it with fresh data. If there is a physical mistake, the impacted data sector is irreversibly damaged.
Databases
Retention policies are included in data integrity, which either guarantees or specifies how long data may be kept in a certain database (usually a relational database). These guidelines must be regularly and consistently adhered to all data accessing the system in order to ensure data integrity; otherwise, inaccuracies in the data may result from inadequate enforcement.
Less inaccurate data enters the system when data checks are implemented as near as feasible to the original point of the input (such as data from human entry). Tight adherence to data integrity guidelines reduces error rates and saves time in debugging and tracking down inaccurate data and the mistakes it introduces into algorithms.
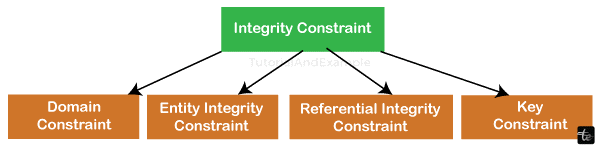
Integrity Constraint Types
A database system's constraints on integrity or rules are often responsible for enforcing data integrity. The relational data architecture is inherently composed of three types of authenticity constraints: entity, referential, and domain integrity.
A primary key is a notion that is related to entity integrity. According to the integrity rule known as "entity integrity," each table needs a primary key, and every column or column designated as the primary key must be distinct and non-null. The foreign key theory is related to referential integrity.
According to the referential integrity rule, a foreign-key value can exist in only one of two states. Typically, the primary key value of a database table is referenced by the foreign key value. A foreign key value may occasionally be null; this will rely on the data owner's policies. Here, we are stating clearly that there is either no link at all between the items that are recorded in the database or that the nature of this relationship is unclear.
According to domain integrity, every column in a database with a relational structure needs to be declared onto a specific domain. The data item is the main data unit within the relational data collection paradigm. These kinds of data elements are said to as atomic or non-decomposable.
The domain name is a collection of identically typed values. Domains are thus collections of values that are used to generate the actual values that show up in a table's columns.
A collection of guidelines established by the user that do not fall under the categories of entity, domain, or referential integrity is known as user-defined integrity.
The database's owner must guarantee data integrity and maintain a uniform model for storing and retrieving information if it provides these characteristics. Applications are responsible for ensuring data integrity when the database supports a unified model for storing and retrieving data if the database does not offer these capabilities.
Stability (a single, centralized system carries out all data integrity actions) performance (the consistency model and all data integrity processes are carried out on the same tier).
- Reusability (having a single, centralized data integrity system benefits all applications).
- Maintainability (one centralized system for managing all aspects of data integrity).
These functionalities are supported by contemporary databases (see Comparison of the management of relational databases systems), and the database is now de facto in charge of maintaining data integrity. Businesses, as well as several database systems, provide services and solutions to help convert antiquated systems to contemporary databases.
Data Integrity in a Variety of Sectors
In order to comply with the U.S. Code of Regulations, 21 CFR Parts 210–212, and pharmaceutical firms must follow draft guidelines on data integrity developed by the U.S. FDA. Similar data integrity guidelines have been released by Australia (2017), Switzerland (2016), and the United Kingdom (2015) outside of the United States.
A number of medical device manufacturing standards, such as ISO 13485, ISO 14155, and ANSI 5840, cover data integrity in direct and indirect ways.
Early in 2017, FINRA (the Financial Industry Regulatory Authority) said that "the establishment of a data integrity program to monitor the accuracy of the supplied data" would be a priority. The agency cited issues with data integrity related to automated trading and money transfer surveillance systems. Treasury securities evaluations and businesses' "modern technology change management plans and procedures" were included in the expansion of FINRA's data integrity methodology announced at the beginning of 2018.
One instance would be text input when date-time information is needed. Data derivation rules, which outline how a data value is obtained based on an algorithm, contributors, and circumstances, are also relevant. It also lays forth the prerequisites for deriving the data value again.
File Systems
Numerous studies' findings indicate that hardware RAID solutions and popular filesystems (such as UFS, Ext, XFS, JFS, and NTFS) are insufficient in guarding against issues with data integrity.
Internal information and metadata check summing is a feature of several filesystems, such as ZFS and Btrfs that is used to improve data integrity and identify silent data damage. These filesystems' inbuilt RAID techniques may be utilized to detect contamination in this manner, and if necessary, they can also transparently restore corrupted data. Better data integrity protection, sometimes referred to as end-to-end data protection, is made possible by this method and covers all data routes.
Data integrity is becoming increasingly important in related automation and production monitoring assets in other industries, such as mining and product manufacture. Cloud storage companies have long struggled with detecting infractions and guaranteeing the provenance or integrity of consumer data.
Foreign Key
A foreign key connects two tables by referencing the main key of one table through a set of characteristics in the first table. The existence of tuples made from the foreign key attributes in a specific relationship, R, must also exist in another relation, S, which need not be distinct. Additionally, those attributes must have a candidate key in S. This inclusion dependency constraint applies to foreign keys in relational databases.
Stated differently, a collection of characteristics that references the potential key is referred to as a foreign key. For instance, a foreign key named MEMBER_NAME, which references a candidate key called PERSON_NAME in the PERSON table, can be included in the TEAM table. Any value that exists as a member's name in City must also exist as the name of that individual in the PERSON database since Membership_NAME is a foreign key; in a nutshell, every person who is part of a TEAM is also a Human.

Rules governing the relationships that a single item of data can have with another are another aspect of data integrity. For example, a customer record may link to products they have purchased but not to irrelevant data like corporate assets. Data integrity frequently involves erroneous data checks and corrections based on predetermined rules or a specified structure.
Important Details to Remember
- There should already be a reference link established.
- The referred attribute needs to be a component of the referenced relation's main key.
- Both the referring and referenced attributes must have the same data type and size.
- Take a database, for instance, that has two tables: an Orders table that contains all of the client orders and a client table that has all of the customer data. The company mandates that every order be associated with a certain client.
- A foreign key column (such as CUSTOMER) is added in the ORDER table, referencing the CUSTOMER primary key (such as ID) in order to represent this in the database. When it includes a value, CUSTOMERID is going to identify the specific customer who purchased since a table's main key needs to be unique and because it only holds values from that main key field.
Working with those tables can get more challenging if rows belonging to the User table are removed or the ID row is changed. However, this ought to no longer be taken into account if an ORDER column is not updated. 'Inactivating' the master table's foreign keys, as opposed to physically removing them, or sophisticated update programs that alter any references to a specific foreign key while an adjustment is required are two common ways that real-world databases get around this issue.
In database architecture, foreign keys are crucial. Ensuring that references to real-world entities are mirrored in the database through the use of foreign keys to link tables is a crucial aspect of database architecture. Database normalization which involves dividing tables and allowing for their reconstruction using foreign keys is a crucial component of database architecture.
The same row in the visited (or parent) table may be referred to by more than one entry in the referring (or child) table. In this instance, the linked table and the table that it references have a relationship that is referred to as a one-several relationship.